SQL CTE vs 서브쿼리: 아직 끝나지 않은 논쟁

SQL을 사용하다 보면 결국 이런 질문에 직면하게 됩니다: 공통 테이블 표현식(CTEs)이 서브쿼리보다 나은가? 이들의 차이점은 무엇인가? 이는 마치 탭과 스페이스, 라이트 모드와 다크 모드, 에스프레소와 익스프레소 사이의 논쟁과 같습니다.
CTE와 서브쿼리는 분명히 다른 개념이며, 단순히 구문 차이만 있는 것이 아닙니다.
두 개념의 차이점과 승자를 알아보기 전에, 각각의 정의부터 명확히 해보겠습니다.
CTE와 서브쿼리 정의
CTEs는 WITH를 사용하여 도입됩니다. 다른 쿼리에서 여러 번 참조할 수 있는 임시 결과입니다. 쿼리가 실행될 때만 사용할 수 있는 임시 테이블이라고 생각하면 됩니다.
서브쿼리는 다른 쿼리 내에 있는 쿼리(정확히는 SELECT 문)입니다. 다음과 같은 구문/절에서 사용할 수 있습니다:
- SELECT
- INSERT
- UPDATE
- DELETE
- WHERE
- HAVING
- FROM
- SET
둘 다 쿼리를 분해하는 동일한 기본 목적을 가지고 있지만, 그 방식이 다릅니다.
대결: CTE vs 서브쿼리
SQL 코딩의 네 가지 측면에서 이 둘을 비교해 보겠습니다. 아래 표는 전체 및 각 라운드의 승자를 보여줍니다.
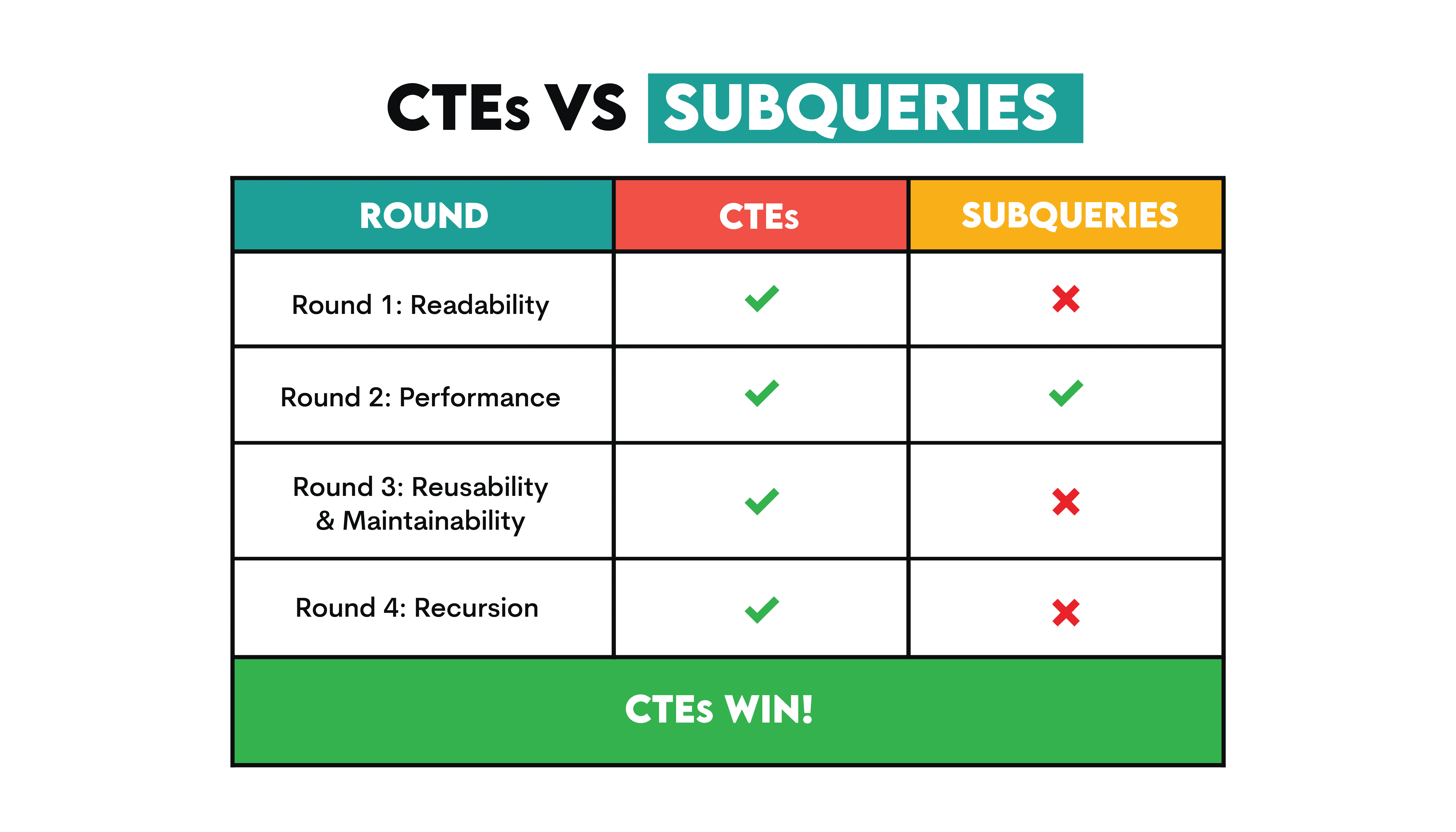
이제 각 라운드의 세부 사항을 살펴보고, CTE가 왜 네 가지 중 세 가지에서 승리했는지 예제와 함께 알아보겠습니다.
라운드 1: 가독성
복잡한 쿼리를 구성하기 위해 서브쿼리에 의존하면 가독성이 떨어지는 코드가 될 수 있습니다. 여러 서브쿼리를 사용하면 상황이 빠르게 통제를 벗어나 디버깅이 악몽이 됩니다.
예를 들어, Meta의 인터뷰 문제를 서브쿼리로 푼 다음 코드를 보세요. 이런 해결책을 설명하기 시작할 지점조차 찾기 어렵습니다.
sql
SELECT country
FROM (
SELECT d.country,
d.dec_rank,
j.jan_rank,
d.totalcomments AS deccomments,
j.totalcomments AS jancomments
FROM (
SELECT country,
total_comments,
DENSERANK() OVER (ORDER BY totalcomments DESC) AS dec_rank
FROM (
SELECT u.country,
SUM(c.numberofcomments) AS total_comments
FROM fbcommentscount AS c
JOIN fbactiveusers AS u ON c.userid = u.userid
WHERE c.created_at >= '2019-12-01'
AND c.createdat < '2020-01-01' GROUP BY u.country ) AS december ) AS d JOIN ( SELECT country, totalcomments, DENSERANK() OVER (ORDER BY totalcomments DESC) AS janrank FROM ( SELECT u.country, SUM(c.numberofcomments) AS totalcomments FROM fbcommentscount AS c JOIN fbactiveusers AS u ON c.userid = u.userid WHERE c.created_at >= '2020-01-01'
AND c.createdat < '2020-02-01' GROUP BY u.country ) AS january ) AS j ON d.country = j.country ) AS rankcompare WHERE decrank > janrank
ORDER BY dec_rank;
이제 CTE를 사용한 해결책과 비교해 보세요. 이 접근법이 반드시 더 짧은 코드를 만들지는 않습니다. 그러나 CTE를 사용하면 코드를 계산이 수행되는 순서에 따라 논리적 블록으로 분해하여 쉽게 이해할 수 있습니다. 각 CTE의 이름 지정도 도움이 됩니다.
sql
WITH monthly_comments AS (
SELECT u.country,
DATETRUNC('month', c.createdat)::DATE AS month_start,
SUM(c.numberofcomments) AS total_comments
FROM fbcommentscount AS c
JOIN fbactiveusers AS u ON c.userid = u.userid
WHERE c.created_at >= '2019-12-01'
AND c.createdat < '2020-02-01' GROUP BY u.country, DATETRUNC('month', c.createdat)::DATE ), december AS ( SELECT country, totalcomments FROM monthlycomments WHERE monthstart = '2019-12-01' ), january AS ( SELECT country, totalcomments FROM monthlycomments WHERE monthstart = '2020-01-01' ), decemberrank AS ( SELECT country, totalcomments, DENSERANK() OVER ( ORDER BY totalcomments DESC) AS decrank FROM december ), januaryrank AS ( SELECT country, totalcomments, DENSERANK() OVER (ORDER BY totalcomments DESC) AS janrank FROM january ), rankcompare AS ( SELECT d.country, d.decrank, j.janrank, d.totalcomments AS deccomments, j.totalcomments AS jancomments FROM decemberrank d JOIN januaryrank j USING (country) ) SELECT country FROM rankcompare WHERE decrank > jan_rank
ORDER BY dec_rank;
판정: CTE 승리
라운드 2: 성능
CTE와 서브쿼리는 일반적으로 성능 면에서 차이가 없습니다. 그러나 서브쿼리가 CTE보다 성능이 떨어지는 경우가 있을 수 있습니다.
이는 서브쿼리의 논리 때문입니다: 서브쿼리는 메인 쿼리에서 참조될 때마다 실행됩니다. 서브쿼리가 여러 번 사용되면(예: 여러 WHERE 또는 JOIN 절에서), 참조될 때마다 평가됩니다. 가능한 결과는 중복 계산으로 인한 실행 시간 증가입니다.
반면 CTE는 쿼리 내에서 한 번만 실행됩니다. CTE가 동일한 쿼리 내에서 여러 번 참조되면 다시 실행하지 않고 CTE 출력을 재사용합니다. 데이터베이스 엔진이 CTE 출력을 임시 결과로 저장하기 때문에 가능합니다(CTE 구체화라고도 함).
그러나 일부 데이터베이스 엔진에서만 이 이점을 경험할 수 있습니다. PostgreSQL과 SQL Server는 CTE 구체화를 잘 처리합니다. MySQL은 항상 CTE를 효율적으로 최적화하지 않으며, Oracle은 때때로 인라인 서브쿼리를 선호합니다.
작은 데이터셋에서는 중요하지 않을 수 있습니다. 그러나 대규모 쿼리와 데이터셋의 경우 CTE가 서브쿼리보다 훨씬 더 나은 성능을 보일 수 있습니다. 또는 그렇지 않을 수도 있습니다. 모두 사용하는 데이터베이스 엔진에 따라 다릅니다.
판정: 무승부
라운드 3: 재사용성 및 유지 관리
동일한 쿼리에서 같은 서브쿼리를 여러 번 복사하여 붙여넣은 경험이 있나요? 그것은 아마도 CTE를 대신 사용했어야 한다는 신호입니다.
CTE는 논리를 한 번만 정의하면 되며, 원하는 만큼 재사용할 수 있습니다. 이렇게 하면 코드 유지 관리가 훨씬 쉬워집니다. 결과가 사용되는 횟수에 관계없이 하나의 CTE만 업데이트하면 됩니다. 반면에 하나의 메인 쿼리에 여러 개의 동일한 서브쿼리가 있으면 각 서브쿼리에서 동일한 업데이트를 수행해야 합니다.
Lyft의 인터뷰 문제를 기반으로 한 예시입니다. 2019년에 가장 수익성이 높은 달이 있는 도시를 찾는 과제라고 가정해 보겠습니다. CTE를 사용하여 이 코드를 작성했습니다.
sql
WITH cte AS (
SELECT city,
EXTRACT(MONTH FROM orderdate) AS pmonth,
SUM(order_fare) AS profit
FROM lyft_orders o
JOIN lyftpaymentdetails p ON o.orderid = p.orderid
WHERE EXTRACT(YEAR FROM order_date) = '2019'
GROUP BY o.city, p_month
)
SELECT city,
p_month,
profit
FROM cte
WHERE profit =
(SELECT MAX(profit)
FROM cte);
여기 결과가 있습니다.

이 보고서를 보낸 지 5분 후, 상사가 2021년이 아닌 2019년에 파리가 가장 수익성이 높은 달을 가졌다는 것이 사실일 수 없다고 주장하며 들어왔습니다. 상사가 2019년이 아닌 2021년이라고 말했나요? 괜찮습니다. '2019'를 '2021'로 바꾸기만 하면 쿼리가 업데이트됩니다.
sql
WITH cte AS (
SELECT city,
EXTRACT(MONTH FROM orderdate) AS pmonth,
SUM(order_fare) AS profit
FROM lyft_orders o
JOIN lyftpaymentdetails p ON o.orderid = p.orderid
WHERE EXTRACT(YEAR FROM order_date) = '2021'
GROUP BY o.city, p_month
)
SELECT city,
p_month,
profit
FROM cte
WHERE profit =
(SELECT MAX(profit)
FROM cte);
여기 올바른 출력이 있습니다.

이제 서브쿼리를 사용한 솔루션은 불필요하게 길어집니다: 동일한 서브쿼리가 두 번 작성되어 있습니다. 이 중복성이 서브쿼리의 첫 번째 단점입니다. 둘째, 위와 같은 실수를 했다면 '2019'를 '2021'로 두 번 변경해야 합니다.
sql
SELECT city, p_month, profit
FROM (
SELECT city,
EXTRACT(MONTH FROM orderdate) AS pmonth,
SUM(order_fare) AS profit
FROM lyft_orders o
JOIN lyftpaymentdetails p ON o.orderid = p.orderid
WHERE EXTRACT(YEAR FROM order_date) = '2021'
GROUP BY o.city, EXTRACT(MONTH FROM order_date)
) AS aggregated_data
WHERE profit = (
SELECT MAX(profit)
FROM (
SELECT city,
EXTRACT(MONTH FROM orderdate) AS pmonth,
SUM(order_fare) AS profit
FROM lyft_orders o
JOIN lyftpaymentdetails p ON o.orderid = p.orderid
WHERE EXTRACT(YEAR FROM order_date) = '2021'
GROUP BY o.city, EXTRACT(MONTH FROM order_date)
) AS maxprofitdata
);
연도를 한 번 대신 두 번 변경하는 것이 그렇게 큰 문제처럼 보이지 않을 수 있습니다. 그러나 이것은 단지 예시일 뿐입니다. 각 서브쿼리가 무엇을 하는지 먼저 파악해야 하는 훨씬 더 복잡한 코드를 상상해 보세요. 그런 다음에야 논리를 변경할 수 있으며, 얼마나 많은 횟수로 이 작업을 수행해야 하는지 알 수 없습니다.
또한 논리의 변경이 예제보다 훨씬 더 복잡할 수 있으므로, 재입력이 아닌 서브쿼리 부분을 복사하여 붙여넣기만 하더라도 후속 서브쿼리에서 실수할 가능성이 증가합니다.
판정: CTE 승리
라운드 4: 재귀
CTE가 서브쿼리보다 갖는 중요한 이점 중 하나는 재귀를 처리할 수 있다는 것입니다. 재귀 쿼리를 사용하면 계층적 데이터(예: 조직 구조, 가족 트리) 및 그래프 기반 데이터(예: 한 도시에서 다른 도시로 가는 최단 또는 최장 경로 찾기)를 쿼리할 수 있습니다.
실제로 SQL에서 진정한 재귀는 CTE로만 달성할 수 있습니다. (자체 조인이나 저장 프로시저 및 루프를 활용하는 대체 방법이 있지만, 이러한 접근 방식에는 계층 깊이를 알 수 없는 경우 작동하지 않거나, 순수 SQL 솔루션이 아니거나, 유지 관리가 충격적으로 어렵거나, CTE보다 훨씬 느리다는 문제가 있습니다.)
예를 들어, ID가 4인 직원이 상사인 모든 직원을 찾기 위해 아래 employees 테이블을 사용해 보겠습니다.
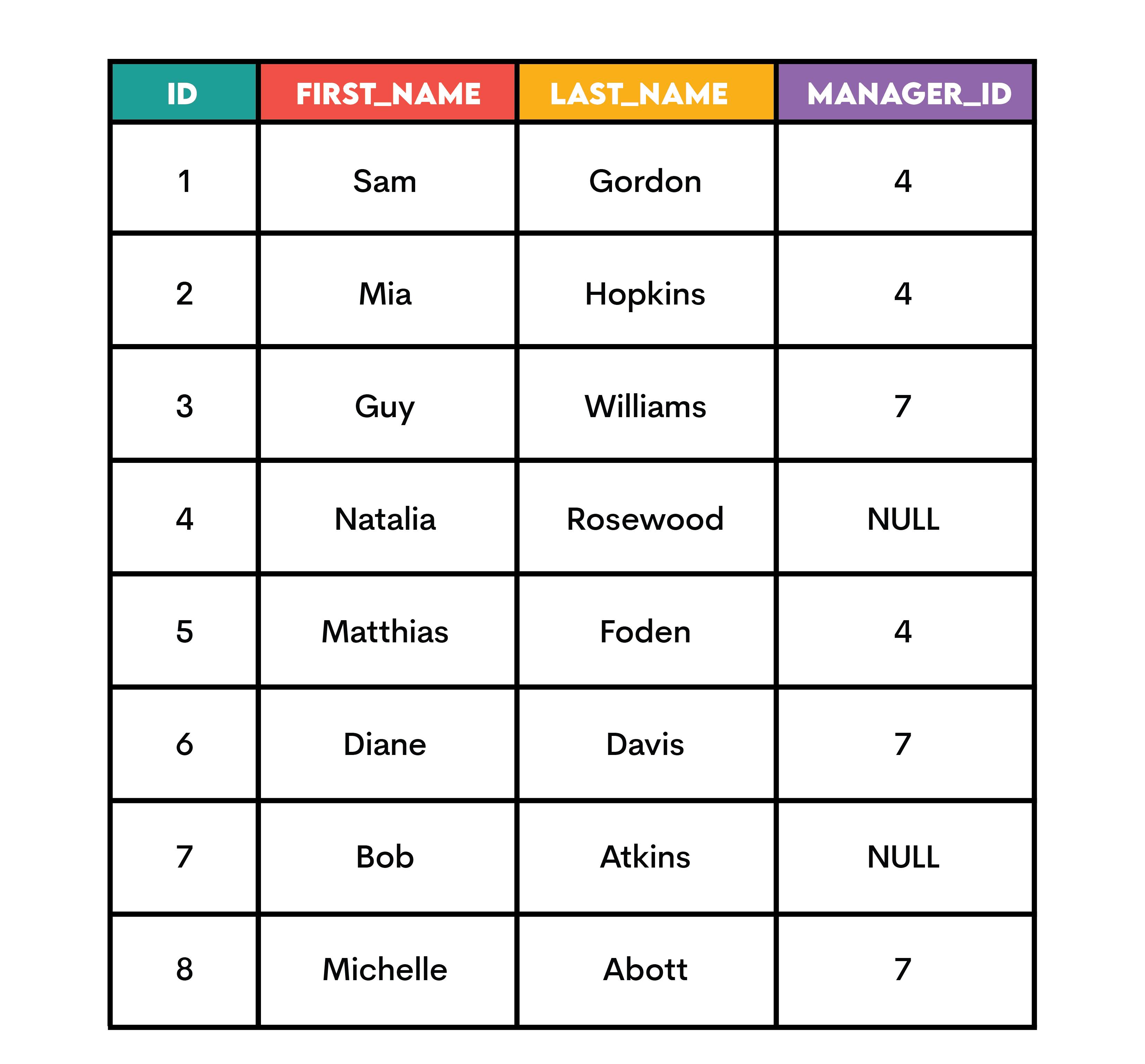
PostgreSQL에서 CTE를 재귀적으로 만들려면 WITH 뒤에 RECURSIVE 키워드를 추가합니다. CTE의 첫 번째 SELECT에서 쿼리는 ID가 4인 직원에 대한 정보를 가져옵니다. 이것은 우리가 찾고 있는 팀원의 상사, 즉 기본을 설정합니다.
이는 관리자의 ID가 팀원의 ID와 같은 곳에서 employees 테이블을 CTE와 조인하는 또 다른 SELECT와 UNION됩니다. 이는 CTE가 자신을 참조한다는 의미(이것이 재귀임)이며 일치하는 항목이 없을 때까지 계속 그렇게 할 것입니다.
외부 SELECT에서는 ID가 4가 아닌 CTE에서 모든 데이터를 선택합니다. 상사 데이터가 아닌 그에게 보고하는 직원만 표시하려고 합니다.
sql
WITH RECURSIVE team_members AS (
SELECT id,
first_name,
last_name,
manager_id
FROM employees
WHERE id = 4
UNION
SELECT e.id,
e.first_name,
e.last_name,
e.manager_id
FROM employees e
JOIN team_members tm
ON e.manager_id = tm.id
)
SELECT *
FROM team_members
WHERE id != 4;
여기 출력이 있습니다.
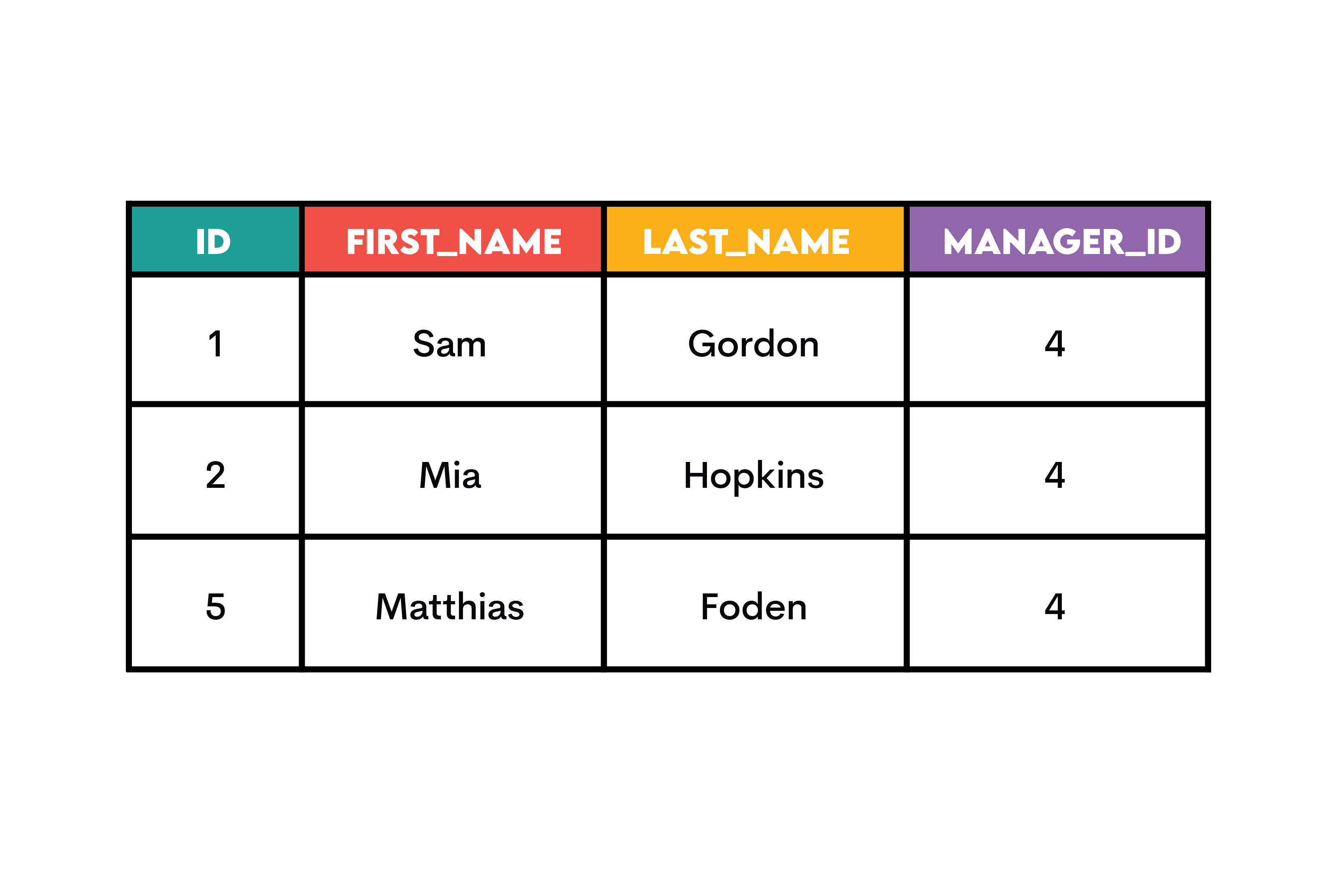
판정: CTE 승리
결론
CTE는 네 가지 대결 중 세 가지에서 승리합니다. 서브쿼리보다 나은 성능을 보이지 않을 수 있는 유일한 경우는 성능입니다. 그러나 이것이 항상 그런 것은 아니므로, 이것이 걱정된다면 둘 다 테스트하여 데이터와 쿼리에 가장 적합한 것을 확인하세요.
CTE는 가독성, 재사용성 및 유지 관리, 그리고 재귀 등 다른 모든 경우에서 명확한 승자입니다.
사람들은 종종 서브쿼리에 고착되는데, 이는 더 복잡한 데이터 하위 집합을 만들고 계산 내에서 계산을 수행해야 하는 코드를 작성할 때 일반적으로 서브쿼리를 먼저 배우기 때문입니다.
제 조언은 CTE로 천천히 전환하는 것입니다: 구문적으로 서브쿼리와 거의 동일하지만(서브쿼리로 작성하는 것과 동일한 SELECT), 이 글에서 보여드린 이점이 있습니다.