VIP 치트시트: 트랜스포머와 대형 언어 모델
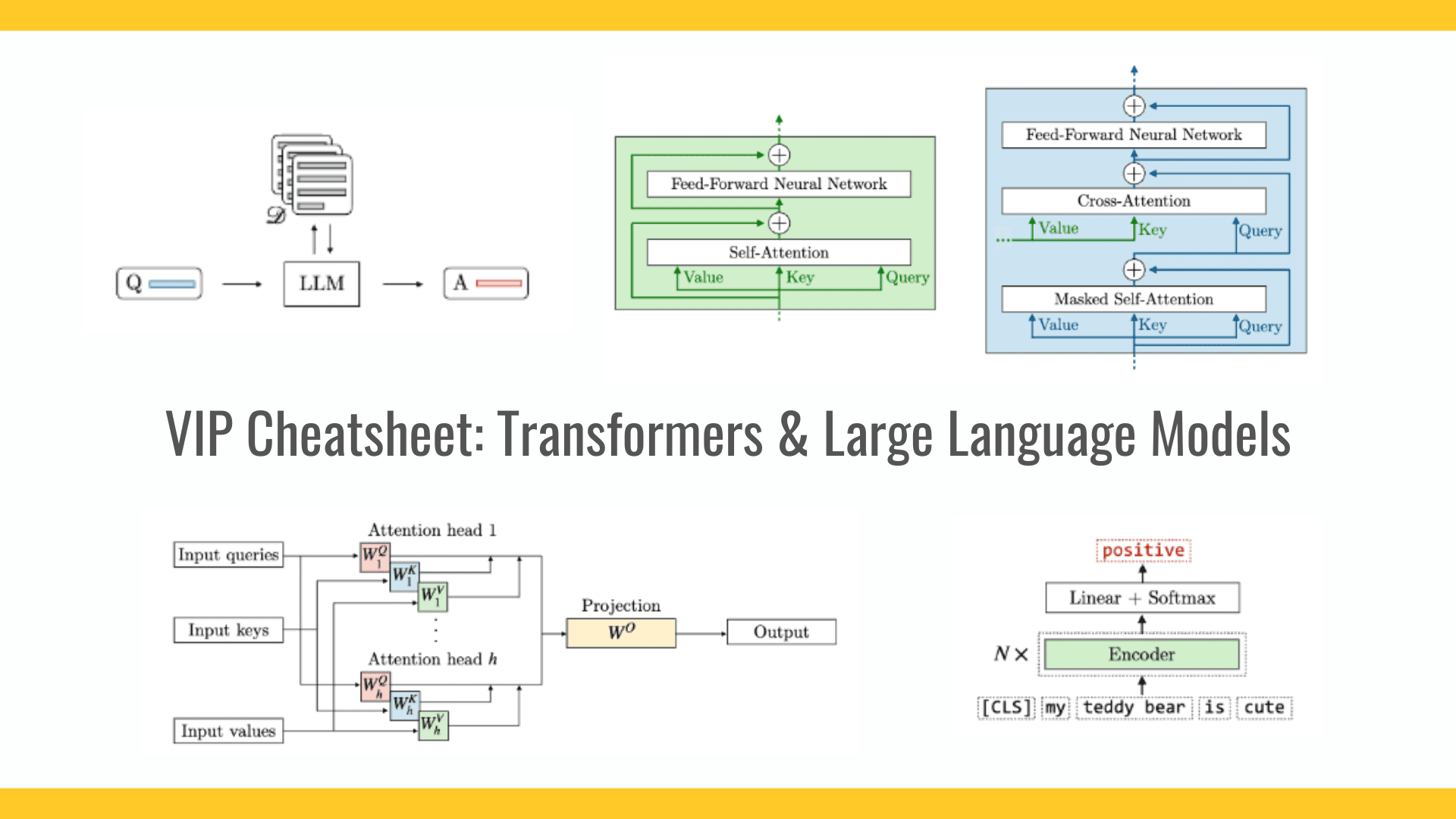
트랜스포머와 대형 언어 모델(LLM)은 현재 큰 주목을 받고 있습니다. 우리는 이러한 기술들에 대해 논의하고, 테스트하며, 작업을 아웃소싱하고, 미세 조정하며, 점점 더 많이 의존하고 있습니다. AI 산업은 날마다 더 많은 실무자들을 맞이하고 있습니다. 우리 모두는 이 개념들에 새롭게 접근하는 사람이든 아니든, 이러한 주제들에 대해 더 많이 배워야 할 필요가 있습니다.
이 글에서는 스탠포드 대학교 CME 295 과정을 위해 Afshine과 Shervine Amidi가 만든 트랜스포머와 대형 언어 모델 VIP 치트시트를 소개하여 이 리소스가 언어 모델을 이해하는 데 도움이 될지 판단하는 데 도움을 드리고자 합니다.
치트시트 개요
이 치트시트는 트랜스포머와 LLM에 대한 간결하면서도 심도 있는 설명을 네 가지 섹션으로 제공합니다: 기초, 트랜스포머, LLM, 응용 분야.

먼저 치트시트의 첫 부분인 기초를 살펴보겠습니다.
기초
기초 섹션에서는 토큰과 임베딩이라는 두 가지 주요 개념을 소개합니다.
토큰은 언어 모델이 사용하는 가장 작은 텍스트 단위입니다. 선택하는 단위에 따라 토큰은 단어, 하위 단어 또는 바이트를 포함할 수 있으며, 이는 토크나이저를 사용하여 처리됩니다. 각 토크나이저는 우리가 기억해야 할 장단점을 가지고 있습니다.
임베딩은 토큰이 의미론적 의미를 담은 수치 벡터로 변환되는 것입니다. 토큰 간의 유사성은 코사인 유사도를 사용하여 측정됩니다. 근사 최근접 이웃(ANN) 및 지역 민감 해싱(LSH)과 같은 근사 방법은 대규모 임베딩 공간에서의 유사성 검색을 확장합니다.
트랜스포머
트랜스포머는 많은 현대 LLM의 핵심입니다. 그들은 각 토큰이 시퀀스 내의 다른 토큰에 주의를 기울일 수 있게 하는 자기 주의 메커니즘을 사용합니다. 이 치트시트는 다음과 같은 많은 개념을 소개합니다:
- 멀티 헤드 어텐션(MHA) 메커니즘은 병렬 주의 계산을 수행하여 다양한 텍스트 관계를 나타내는 출력을 생성합니다.
- 트랜스포머는 인코더 및/또는 디코더 스택으로 구성되며, 이는 단어 순서를 이해하기 위해 위치 임베딩을 사용합니다.
- 분류에 적합한 BERT와 같은 인코더 전용 모델, 텍스트 생성에 중점을 둔 GPT와 같은 디코더 전용 모델, 번역 작업에 뛰어난 T5와 같은 인코더-디코더 모델 등 여러 아키텍처 변형이 있습니다.
- 플래시 어텐션, 스파스 어텐션, 저차원 근사와 같은 최적화는 모델을 더 효율적으로 만듭니다.
대형 언어 모델
LLM 섹션에서는 사전 훈련, 지도 미세 조정 및 선호도 조정으로 구성된 모델 수명 주기에 대해 논의합니다. 또한 다음과 같은 많은 추가 개념이 논의됩니다:
- 컨텍스트 길이 및 출력과 같은 프롬프팅 개념은 온도를 통해 제어할 수 있습니다. 또한 모델이 추론 단계를 생성하고 복잡한 작업을 더 효과적으로 해결할 수 있게 하는 생각의 사슬(CoT) 및 생각의 트리(ToT) 기법에 대해서도 논의합니다.
- 미세 조정에는 지도 미세 조정(SFT)과 명령어 조정을 포함한 여러 접근 방식이 있으며, 매개변수 효율적 미세 조정(PEFT) 아래에 표시된 LoRA와 프리픽스 튜닝과 같은 더 효율적인 방법도 있습니다.
- 선호도 조정은 보상 모델(RM)을 사용하여 모델을 정렬하며, 이는 종종 인간 피드백으로부터의 강화 학습(RLHF) 또는 직접 선호도 최적화(DPO)를 통해 학습됩니다. 이러한 단계는 모델 출력이 정확함을 보장합니다.
- MoE 모델과 같은 최적화 기술은 모델 구성 요소의 일부만 활성화하여 계산을 줄입니다. 증류는 더 큰 모델에서 더 작은 모델을 훈련시키고, 양자화는 더 빠른 추론을 위해 가중치를 압축합니다. QLoRA는 양자화와 LoRA를 결합합니다.
응용 분야
마지막으로, 응용 분야에서는 네 가지 주요 사용 사례를 논의합니다:
- LLM-as-a-Judge는 참조와 독립적으로 출력을 평가하기 위해 LLM을 사용하며, 이는 주관적인 평가가 포함된 작업에 유용합니다.
- 검색 증강 생성(RAG)은 LLM이 텍스트를 생성하기 전에 관련 외부 지식에 접근할 수 있도록 하여 LLM 응답을 개선합니다.
- LLM 에이전트는 ReAct를 활용하여 연쇄 작업에서 자율적으로 계획, 관찰 및 행동합니다.
- 추론 모델은 구조화된 추론과 단계별 사고를 사용하여 복잡한 문제를 해결합니다.
트랜스포머와 언어 모델은 간결하게 다루어지며, 검토와 소개 목적 모두에 적합합니다.