에이전트형 AI의 코딩 잠재력에 대한 벤치마크 평가

에이전트형 AI의 코딩 능력 향상
지난주 GTC 2025 쇼는 에이전트형 AI의 획기적인 순간이었을지 모르지만, 이 기술의 핵심은 조용히 발전해 왔습니다. 이러한 발전은 SWE-bench와 GAIA와 같은 여러 코딩 벤치마크를 통해 추적되고 있으며, 이로 인해 AI 에이전트가 큰 변화의 문턱에 있다고 보는 사람들이 늘고 있습니다.
얼마 전까지만 해도 AI가 생성한 코드는 배포에 적합하지 않다고 여겨졌습니다. SQL 코드가 너무 장황하거나 Python 코드에 버그가 있거나 보안이 취약했습니다. 그러나 최근 몇 개월 동안 이 상황은 크게 변화했으며, 오늘날의 AI 모델은 매일 더 많은 코드를 고객을 위해 생성하고 있습니다.
벤치마크는 에이전트형 AI가 소프트웨어 엔지니어링 분야에서 얼마나 발전했는지 측정하는 좋은 방법을 제공합니다. 가장 인기 있는 벤치마크 중 하나인 SWE-bench는 프린스턴 대학교 연구자들이 만들었으며, Meta의 Llama와 Anthropic의 Claude 같은 LLM이 일반적인 소프트웨어 엔지니어링 문제를 얼마나 잘 해결하는지 측정합니다. 이 벤치마크는 16개 저장소에 걸친 Python 소프트웨어 버그의 풍부한 리소스로 GitHub을 활용하고, LLM 기반 AI 에이전트가 이를 얼마나 잘 해결하는지 측정하는 메커니즘을 제공합니다.
2023년 10월 연구자들이 "SWE-Bench: Can Language Models Resolve Real-World GitHub Issues?"라는 논문을 ICLR(International Conference on Learning Representations)에 제출했을 때, LLM은 높은 수준의 성능을 보이지 않았습니다. "우리의 평가에 따르면 최신 독점 모델과 우리가 미세 조정한 SWE-Llama 모델은 가장 간단한 문제만 해결할 수 있습니다," 저자들은 초록에 적었습니다. "최고 성능 모델인 Claude 2는 단지 1.96%의 문제만 해결할 수 있었습니다."
하지만 이는 빠르게 변화했습니다. 오늘날 SWE-bench 리더보드에 따르면, 최고 점수 모델은 SWE-bench Lite(평가를 더 저렴하고 접근하기 쉽게 만들기 위해 설계된 벤치마크의 하위 집합)에서 코딩 문제의 55%를 해결했습니다.
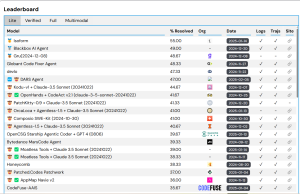
Huggingface는 GAIA(General AI Assistants를 위한 벤치마크)를 만들었으며, 이는 추론, 다중 모달리티 처리, 웹 브라우징, 그리고 일반적인 도구 사용 능력 등 여러 영역에서 모델의 역량을 측정합니다. GAIA 테스트는 모호하지 않고 도전적이며, 예를 들어 5분짜리 비디오에서 새의 수를 세는 작업 같은 것이 포함됩니다.
H2O.ai의 CEO이자 공동 설립자인 Sri Ambati에 따르면, 1년 전 GAIA 테스트 레벨 3의 최고 점수는 약 14였습니다. 오늘날 Claude 3.7 Sonnet 기반의 H2O.ai 모델이 약 53의 총점으로 최고 점수를 보유하고 있습니다.
"정확도가 정말 빠르게 성장하고 있습니다," Ambati는 말했습니다. "아직 완전히 도달하지는 않았지만, 우리는 그 길에 있습니다."
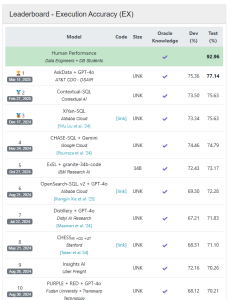
H2O.ai의 소프트웨어는 SQL 생성을 측정하는 또 다른 벤치마크에도 관여하고 있습니다. BIRD(BIg Bench for LaRge-scale Database Grounded Text-to-SQL Evaluation)는 AI 모델이 자연어를 SQL로 얼마나 잘 파싱하는지 측정합니다.
2023년 5월 BIRD가 데뷔했을 때, 최고 점수 모델인 CoT+ChatGPT는 약 40%의 정확도를 보여주었습니다. 1년 전, IBM의 Granite AI 모델 기반의 최고 점수 AI 모델인 ExSL+granite-20b-code는 약 68%의 정확도를 가졌습니다. 이는 BIRD가 약 92%로 측정한 인간 성능에 비해 상당히 낮았습니다. 현재 BIRD 리더보드는 AT&T의 H2O.ai 기반 모델이 77%의 정확도로 선두를 보여주고 있습니다.
괜찮은 컴퓨터 코드 생성의 빠른 발전은 Nvidia CEO이자 공동 설립자인 Jensen Huang과 Anthropic 공동 설립자이자 CEO인 Dario Amodei와 같은 영향력 있는 AI 리더들이 우리의 가까운 미래에 대해 대담한 예측을 하게 만들었습니다.
"우리는 AI가 코드의 90%를 작성하는 세계에서 멀지 않습니다—저는 3~6개월 안에 그럴 것이라고 생각합니다," Amodei는 이번 달 초에 말했습니다. "그리고 12개월 내에, 우리는 AI가 본질적으로 모든 코드를 작성하는 세계에 있을 수 있습니다."
지난주 GTC25 기조연설에서, Huang은 에이전트 컴퓨팅의 미래에 대한 그의 비전을 공유했습니다. 그의 관점에서, 우리는 인간이 데이터를 검색하고 조작하기 위한 소프트웨어를 작성하는 대신, AI 팩토리가 인간 입력을 기반으로 소프트웨어를 생성하고 실행하는 세계에 빠르게 접근하고 있습니다.
"과거에는 우리가 소프트웨어를 작성하고 그것을 컴퓨터에서 실행했지만, 미래에는 컴퓨터가 소프트웨어를 위한 토큰을 생성할 것입니다," Huang은 말했습니다. "그래서 컴퓨터는 파일을 검색하는 것이 아니라 토큰을 생성하는 도구가 되었습니다. [우리는] 검색 기반 컴퓨팅에서 생성 기반 컴퓨팅으로 전환했습니다."
다른 이들은 더 현실적인 견해를 취하고 있습니다. Snowflake의 주요 연구 과학자이자 Snowflake AI 연구팀 리더인 Anupam Datta는 SQL 생성의 향상을 칭찬합니다. 예를 들어, Snowflake는 자사의 Cortex Agent의 텍스트-SQL 생성 정확도가 92%라고 말합니다. 그러나 Datta는 컴퓨터가 올해 말까지 스스로 코드를 작성할 것이라는 Amodei의 견해를 공유하지 않습니다.
"제 견해로는 텍스트-SQL과 같은 특정 영역에서의 코딩 에이전트가 정말 좋아지고 있습니다," Datta는 지난주 GTC25에서 말했습니다. "다른 특정 영역에서는, 그들은 프로그래머가 더 빨리 일할 수 있도록 돕는 조수일 뿐입니다. 인간은 아직 루프에서 완전히 벗어나지 않았습니다."
코딩 공동 파일럿과 에이전트형 AI 시스템 덕분에 프로그래머 생산성이 크게 향상될 것이라고 그는 말했습니다. 우리는 에이전트형 AI가 첫 초안을 생성하고, 그 다음 인간이 들어와서 이를 개선하는 세계와 멀지 않습니다. "생산성에 엄청난 향상이 있을 것입니다," Datta가 말했습니다. "따라서 공동 파일럿만으로도 영향은 매우 중요할 것입니다."
H2O.ai의 Ambati도 소프트웨어 엔지니어가 AI와 긴밀하게 협력할 것이라고 믿습니다. 오늘날 최고의 코딩 에이전트도 "미묘한 버그"를 도입하므로, 사람들은 여전히 코드를 검토할 필요가 있다고 그는 말했습니다. "여전히 꽤 필요한 기술 세트입니다."
아직 초기 단계인 한 영역은 자연어가 비즈니스 맥락으로 번역되는 시맨틱 레이어입니다. 문제는 영어가 모호할 수 있으며, 같은 구문에서 여러 의미를 가질 수 있다는 것입니다.
"그 일부는 고객 스키마의 시맨틱 레이어, 메타데이터를 이해하는 것입니다," Ambati는 말했습니다. "그 부분은 아직 구축 중입니다. 그 온톨로지는 여전히 다소 도메인 지식입니다."
환각(hallucination)도 여전히 문제이며, AI 모델이 탈선하여 나쁜 말을 하거나 행동할 가능성도 있습니다. 이는 모두 Anthropic, Nvidia, H2O.ai, Snowflake와 같은 회사들이 완화하기 위해 노력하고 있는 우려 영역입니다. 그러나 생성형 AI의 핵심 능력이 향상됨에 따라 AI 에이전트를 프로덕션에 투입하지 않는 이유의 수는 감소하고 있습니다.