MLPerf v5.0, AI 추론에서 추론 능력으로의 전환을 반영

(출처: ArtemisDiana/Shutterstock)
생성형 AI가 추론 환경을 재구성하고 있다는 점에 의심의 여지가 있었다면, 최신 MLPerf 결과가 그 의문을 해소할 것입니다. MLCommons는 오늘 업계 표준인 MLPerf Inference v5.0 벤치마크 스위트의 새로운 결과를 발표했습니다. 처음으로 대규모 언어 모델이 전통적인 이미지 분류를 제치고 가장 많이 제출된 워크로드가 되었으며, Meta의 Llama 2 70B가 오랫동안 지배해온 ResNet-50 벤치마크를 대체했습니다.
이러한 변화는 성능, 지연 시간 및 규모가 이제 에이전트 추론(agentic reasoning)과 MLPerf에서 벤치마킹한 것 중 가장 큰 모델인 Llama 3.1 405B와 같은 대규모 모델의 요구 사항을 고려해야 하는 새로운 벤치마킹 시대를 열었습니다.
업계 리더들은 분산 추론, FP4 정밀도 및 저지연 성능에 최적화된 새로운 하드웨어와 소프트웨어로 생성형 AI 붐에 대응했습니다. 이러한 초점은 최신 MLPerf 결과에서 볼 수 있듯이 커뮤니티가 양쪽 전선에서 얼마나 빠르게 발전하고 있는지 보여주는 극적인 성과를 이끌어냈습니다.
분야와 함께 진화하는 벤치마킹 프레임워크
MLPerf Inference 작업 그룹은 모델이 빠르게 진화함에 따라 더욱 어려워지고 있는 작업인 실제 워크로드를 대표하면서 아키텍처에 중립적이고 재현 가능한 방식으로 기계 학습 성능을 평가하기 위한 벤치마크를 설계합니다. 최신 상태를 유지하기 위해 MLCommons는 새로운 벤치마크 추가 속도를 높였으며, 채팅봇과 같은 지연 시간 제약이 있는 서버, 처리량 중심의 오프라인, 스트리밍 모드와 같은 여러 시나리오에서 데이터 센터 및 엣지 배포를 모두 다룹니다.
공정한 비교를 보장하기 위해 각 MLPerf 벤치마크에는 정확한 모델 버전, 입력 데이터, 사전 처리 파이프라인 및 정확도 요구 사항을 정의하는 상세한 사양이 포함됩니다. 제출물은 사과 대 사과 비교를 허용하기 위해 엄격하게 통제되는 "클로즈드" 부문이나 알고리즘 및 아키텍처 유연성을 허용하지만 직접 비교할 수 없는 "오픈" 부문으로 나뉩니다. 클로즈드 부문은 회사가 시스템 및 소프트웨어 최적화에만 경쟁할 수 있도록 하는 반면, 오픈 부문은 새로운 아키텍처 및 새로운 모델 설계를 위한 시험대 역할을 합니다.
버전 5.0에서 대부분의 활동은 클로즈드 데이터센터 카테고리에 남아 있었으며, 23개 조직이 약 18,000개의 결과를 제출했습니다. 모든 카테고리에 대한 제출자에는 AMD, ASUSTeK, Broadcom, cTuning Foundation, Cisco, CoreWeave, Dell Technologies, FlexAI, Fujitsu, GATEoverflow, Giga Computing, Google, HPE, Intel, KRAI, Lambda, Lenovo, MangoBoost, Nvidia, Oracle, Quanta Cloud Technology, Supermicro 및 Sustainable Metal Cloud가 포함됩니다.

Llama 2 70B의 성능 결과는 1년 전보다 급증했습니다: 중앙값 제출 점수는 두 배가 되었고, 최고 점수는 Inference v4.0에 비해 3.3배 더 빨라졌습니다. (출처: MLCommons)
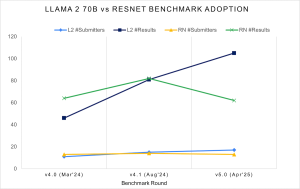
지난 1년 동안 Llama 2 70B 벤치마크 테스트에 대한 제출이 2.5배 증가했으며, 이는 널리 참조되는 오픈 소스 모델을 기반으로 대규모 생성형 AI 추론 워크로드를 구현합니다. v5.0 출시와 함께 Llama 2 70B가 이제 가장 높은 제출률 테스트로 Resnet50을 대체했습니다. (출처: MLCommons)
이번 라운드에서 성능 진화의 가장 명확한 신호 중 하나는 FP4, 즉 추론의 메모리 및 컴퓨팅 오버헤드를 극적으로 줄이는 4비트 부동 소수점 형식과 같은 낮은 정밀도 계산 형식으로의 전환에서 나왔습니다. MLCommons는 Llama 2 70B에 대한 중앙값 성능 점수가 작년에 비해 두 배가 되었고, 최상의 경우 결과는 3.3배 향상되었다고 보고했습니다. 이러한 이득은 부분적으로 시스템 전반에 걸친 FP4 지원 증가에 의해 주도되었습니다. MLPerf의 엄격한 정확도 제약은 실제 필터 역할을 합니다: 낮은 정밀도에서 얻은 성능 향상은 여전히 확립된 정확도 임계값을 충족해야 합니다. 결과는 FP4가 더 이상 실험적인 것이 아니라 생산 추론에서 실행 가능한 성능 레버가 되고 있음을 시사합니다.
"이는 이 형식의 능력을 보여줍니다," MLPerf Inference 작업 그룹의 공동 의장인 Miro Hodak은 언론 브리핑에서 말했습니다. "훨씬 낮은 수치 형식을 사용하더라도 시스템은 여전히 우리의 정확도와 품질 목표를 충족하는 결과를 생성할 수 있습니다."

(출처: MLCommons)
새로운 워크로드, 추론 영역 확장 반영
AI 워크로드의 빠른 진화에 발맞추기 위해 MLCommons는 한 번의 라운드에서 가장 큰 확장을 위해 MLPerf Inference v5.0에 네 가지 새로운 벤치마크를 도입했습니다. 중심에는 MLPerf에 포함된 가장 야심찬 벤치마크인 Llama 3.1 405B가 있습니다. 4,050억 개의 매개변수와 최대 128,000개의 컨텍스트 토큰(Llama 2 70B의 4,096개와 비교)을 지원하는 이 벤치마크는 일반 질의응답, 수학적 추론 및 코드 생성이 혼합된 시스템에 도전합니다.
"이것은 현재까지 우리의 가장 야심찬 추론 벤치마크입니다," Hodak은 보도자료에서 말했습니다. "이는 더 큰 모델로 향하는 업계 트렌드를 반영하며, 이는 정확도를 높이고 더 넓은 범위의 작업을 지원할 수 있습니다. 이는 더 어렵고 시간이 많이 걸리는 테스트이지만, 조직들은 이 정도 규모의 실제 모델을 배포하려고 노력하고 있습니다. 신뢰할 수 있고 관련성 있는 벤치마크 결과는 그들이 최선의 배포 방법에 대해 더 나은 결정을 내리는 데 매우 중요합니다."

(출처: MLCommons)
이 스위트는 또한 채팅봇 및 에이전트 AI 시스템과 같이 빠른 응답이 중요한 실제 애플리케이션을 모델링하도록 설계된 Llama 2 70B Interactive라는 Llama 2 70B의 새로운 변형도 추가합니다. 이 시나리오에서 시스템은 처리량뿐만 아니라 첫 번째 토큰을 빠르게 전달하는 능력(첫 번째 토큰까지의 시간)과 높은 토큰 전달 속도(출력 토큰당 시간)를 유지하는 능력도 평가되며, 둘 다 사용자 경험에 중요합니다.
"쿼리 시스템이나 채팅봇의 성능을 측정하는 중요한 척도는 그것이 상호작용하는 사람에게 반응적으로 느껴지는지 여부입니다. 프롬프트에 얼마나 빨리 응답하기 시작하고, 어떤 속도로 전체 응답을 전달하나요?" MLPerf Inference 작업 그룹 공동 의장인 Mitchelle Rasquinha가 말했습니다. "응답성에 대한 더 엄격한 요구 사항을 적용함으로써, Llama 2 70B 테스트의 이 대화형 버전은 실제 시나리오에서 LLM의 성능에 대한 새로운 통찰력을 제공합니다."
대규모 언어 모델 외에도 MLPerf 5.0은 새롭게 부상하는 사용 사례를 포착하기 위해 두 가지 새로운 벤치마크도 도입했습니다. Illinois Graph Benchmark Heterogeneous 데이터세트에서 훈련된 대규모 그래프 신경망(GNN) 모델을 기반으로 한 RGAT 벤치마크는 시스템이 그래프 기반 추론 작업을 얼마나 잘 처리할 수 있는지 평가합니다. 이러한 워크로드는 사기 탐지, 추천 시스템 및 약물 발견에서 점점 더 관련성이 있습니다.
Automotive PointPainting 벤치마크는 자율 주행 차량에 사용되는 엣지 시스템을 대상으로 하는 새로운 추가 사항을 완성합니다. 이는 3D 객체 감지를 위해 카메라와 LiDAR 입력을 결합하는 복잡한 센서 융합 시나리오를 시뮬레이션합니다. MLCommons가 더 넓은 자동차 제품군 작업을 계속하는 동안, 이 벤치마크는 필드에서 안전이 중요한 비전 작업의 프록시 역할을 합니다.
Nvidia, Blackwell 및 에이전트 준비 인프라 전시
일관되게 MLPerf 제출을 주도해 온 Nvidia는 새로운 Blackwell 아키텍처의 초기 결과를 선보였습니다. 72개의 NVIDIA Blackwell GPU를 연결하여 단일 대규모 GPU처럼 작동하는 GB200 NVL72 시스템은 이번 라운드의 NVIDIA H200 NVL8 제출보다 Llama 3.1 405B 벤치마크에서 최대 30배 높은 처리량을 제공했습니다. 검증되지 않은 제출에서 Nvidia는 전체 랙 GB200 NVL72 시스템이 Llama 2 70B를 실행할 때 초당 거의 900,000개의 토큰을 달성했다고 말했으며, 이는 다른 어떤 시스템도 근접하지 못한 수치입니다.
이제 3년이 되었지만 여전히 널리 사용 가능한 Hopper는 일부 벤치마크에서 지난해보다 60% 향상된 성능을 보였으며, 이는 소프트웨어 최적화가 계속해서 성능의 의미 있는 동인이 되고 있음을 상기시킵니다. MLPerf Inference v4.0에서 1년 전에 처음 도입된 Llama 2 70B 벤치마크에서 H100 GPU 처리량은 1.5배 증가했습니다. 더 크고 빠른 GPU 메모리를 갖춘 동일한 Hopper GPU 아키텍처 기반의 H200 GPU는 그 증가를 1.6배로 확장합니다. 또한 Hopper는 회사가 블로그 포스트에서 밝힌 바와 같이 새로 추가된 Llama 3.1 405B, Llama 2 70B Interactive 및 그래프 신경망 테스트를 포함한 모든 벤치마크를 실행했습니다.
Nvidia는 MLPerf 결과를 다음 프론티어로 보는 추론 AI에 대해 이야기하기 위한 발판으로 사용했습니다. 이 새롭게 부상하는 카테고리에서 생성형 시스템은 단순히 생성하는 것이 아니라 프롬프트 체인, 큰 컨텍스트 윈도우, 때로는 혼합 전문가(MOE)라고 불리는 조정된 여러 모델을 사용하여 다단계 작업을 계획, 결정 및 실행합니다. Llama 3.1과 같은 대형 모델(최대 120,000개 토큰의 입력 시퀀스 길이 지원)은 Nvidia가 "긴 사고 시간"이라고 부르는 것의 도래를 알립니다. 모델은 이전 세대보다 훨씬 더 많은 정보를 처리, 추론하고 종합해야 합니다.
이러한 기능에는 엄격한 인프라 요구 사항이 따릅니다. 모델이 크기와 복잡성이 증가함에 따라 추론은 GPU, CPU, 네트워킹 및 오케스트레이션 계층에 걸친 전체 스택, 다중 노드 과제가 되고 있습니다: "점점 더 추론은 단일 GPU 문제가 아닙니다. 경우에 따라서는 단일 서버 문제도 아닙니다. 이는 전체 스택 다중 노드 과제입니다," Nvidia의 Accelerated Computing Group의 가속 컴퓨팅 제품 책임자인 Dave Salvator가 언론 브리핑에서 말했습니다.
Nvidia가 강조한 핵심 최적화는 컴퓨팅 집약적인 "프리필" 단계와 메모리 바인딩된 "디코드" 단계의 분리, 즉 분리된 서빙입니다. 또한 이 회사는 FP4 작업이 향후 전략의 초석임을 지적했습니다. DeepSeek-V3 추론 모델의 첫 번째 FP4 구현에서 Nvidia는 1% 미만의 정확도 손실로 5배 이상의 속도 향상을 주장했습니다.
에코시스템 전반에 걸쳐 모멘텀 구축
Nvidia가 Blackwell 벤치마크로 많은 관심을 받았지만, LLM 추론 및 시스템 최적화에서 새로운 영역을 개척한 유일한 회사는 아니었습니다. MLPerf Inference v5.0에는 AMD, Intel, Google 및 Broadcom뿐만 아니라 생성형 AI 스택에서 역할을 담당하고자 하는 소규모 기업 및 스타트업의 경쟁력 있는 제출도 있었습니다.
AMD는 새로운 Instinct MI325X 가속기를 사용하여 결과를 제출했으며, 여러 LLM 벤치마크에서 경쟁력 있는 성능을 보여주었습니다. MI325X는 MLPerf에서 벤치마킹된 AMD의 업데이트된 MI300X GPU 시리즈 중 첫 번째이며 FP4를 지원합니다. Supermicro, ASUSTeK, Giga Computing 및 MangoBoost를 포함한 여러 파트너가 AMD 하드웨어를 사용하여 결과를 제출했습니다. MI325X를 사용한 파트너 제출은 Llama 2 70B에서 AMD 자체 결과와 일치하여 하드웨어 및 소프트웨어 스택의 성숙도와 신뢰성을 강화했습니다. AMD는 또한 MI325X에서 Stable Diffusion XL을 벤치마킹하여 생성형 추론 성능을 향상시키기 위해 GPU 파티셔닝 기술을 사용했습니다.
Intel은 특히 그래프 신경망(GNN) 및 추천 워크로드에 대해 6세대 Xeon CPU를 실행 가능한 AI 추론 엔진으로 계속 포지셔닝했습니다. 6개의 벤치마크에서 Xeon 6 CPU는 이전 세대보다 1.9배 향상된 성능을 제공했으며, Intel이 2021년 처음으로 MLPerf에 참가한 이후 최대 15배의 성능 향상을 보인 추세를 이어갔습니다. 이 회사는 고전적인 기계 학습부터 중간 규모의 딥 러닝 모델 및 그래프 기반 추론에 이르기까지 다양한 워크로드에서 성능 향상을 보여주었습니다. Intel은 다시 한 번 독립형 서버 CPU 결과를 제출한 유일한 공급업체였으며, 또한 많은 가속 시스템에서 호스트 프로세서 역할을 했습니다. 제출은 Cisco, Dell Technologies, Quanta 및 Supermicro와의 파트너십을 통해 지원되었습니다.
Google Cloud는 Inference v5.0에서 15개의 결과를 제출했으며, GPU 및 TPU 기반 인프라 모두에서 발전을 강조했습니다. Google은 처음으로 NVIDIA H200 GPU로 구동되는 A3 Ultra VM과 미리보기에서 NVIDIA B200 GPU를 갖춘 A4 VM의 결과를 제출했습니다. A3 Ultra는 높은 메모리 대역폭과 GPU 상호연결 속도를 활용하여 대규모 언어 모델, 혼합 전문가 및 비전 워크로드 전반에 걸쳐 강력한 성능을 제공했습니다. A4 결과도 비교 가능한 제출 중에서 좋은 위치를 차지했습니다. Google은 또한 6세대 TPU인 Trillium의 두 번째 라운드 결과를 가지고 돌아왔으며, TPU v5e에 비해 Stable Diffusion XL에서 3.5배의 처리량 향상을 제공했습니다.
Broadcom은 새로 도입된 RGAT 벤치마크에서 두드러졌으며, 이는 단백질 접힘 및 재료 발견과 같은 실제 과학 애플리케이션을 반영하도록 설계된 그래프 신경망 작업입니다. Broadcom은 자사의 가속기 아키텍처가 특히 희소하고 구조화된 데이터 작업에 적합하다고 말했으며, 이 기회를 활용하여 AI 전략을 더욱 확고하게 "과학을 위한 AI" 도메인 내에 위치시켰습니다.
이번 라운드에서는 MangoBoost, Lambda, FlexAI 및 GATEoverflow를 포함한 소규모 공급업체 및 스타트업의 참여가 급증했으며, 그 중 일부는 MLPerf 벤치마크 프로세스에 새롭게 합류했습니다. 그들의 제출은 생성형 AI 추론이 가장 큰 하이퍼스케일러의 독점 영역이 아님을 검증하는 데 도움이 되었습니다. 특히 MangoBoost와 Lambda는 긴밀하게 통합된 하드웨어-소프트웨어 스택이 독점 클라우드 환경 외부에서도 오픈 소스 모델에 대한 저지연 성능을 제공할 수 있는 방법을 보여주는 결과를 제출했습니다.
"Inference 벤치마크에 처음 참여한 다섯 제출자인 CoreWeave, FlexAI, GATEOverflow, Lambda 및 MangoBoost를 환영하고 싶습니다," MLCommons의 MLPerf 책임자인 David Kanter가 말했습니다. "제출자 커뮤니티의 지속적인 성장은 AI 커뮤니티에 정확하고 신뢰할 수 있는 성능 지표의 중요성을 증명합니다. 또한 이번 라운드에서 Fujitsu의 광범위한 데이터센터 전력 벤치마크 제출과 GateOverflow의 엣지 전력 제출을 강조하고 싶습니다. 이는 AI 시스템의 에너지 효율성이 점점 더 중요한 문제가 되고 있으며 의사 결정을 안내하기 위한 정확한 데이터가 필요하다는 것을 상기시킵니다."
최신 MLPerf Inference v5.0 결과는 업계가 AI 워크로드를 어떻게 재정의하고 있는지를 반영합니다. 이러한 결과 전반에서 가장 눈에 띄는 점 중 하나는 소프트웨어의 역할이었습니다. 많은 공급업체가 동일한 하드웨어에서도 MLPerf 4.0에 비해 개선된 점수를 게시했으며, 이는 컴파일러, 런타임 라이브러리 및 양자화 전략 형태의 최적화가 계속해서 성능 향상을 이끌고 있음을 강조합니다.
오늘날의 추론은 하드웨어 및 소프트웨어 스택 전반에 걸쳐 복잡성을 관리하는 것을 의미하며, 처리량과 지연 시간뿐만 아니라 실시간으로 계획, 추론 및 생성하는 추론 모델에 대한 적응성도 측정합니다. FP4와 같은 새로운 형식이 인기를 얻고 에이전트 AI가 더 큰 컨텍스트 윈도우와 더 많은 오케스트레이션을 요구함에 따라 벤치마크는 모델 실행뿐만 아니라 인프라 설계에 관한 것이 되고 있습니다. MLCommons가 다음 라운드를 준비함에 따라 공급업체들은 단순히 성능을 발휘할 뿐만 아니라 추론 스택의 모든 계층을 재구성하는 생성형 시대와 보조를 맞춰야 하는 압력을 받을 것입니다.
전체 MLPerf Inference v5.0 결과를 보려면 데이터센터 및 엣지 벤치마크 결과 페이지를 방문하세요.
아래는 MLPerf 제출자의 공급업체 성명서입니다(일부 편집됨).
---
AMD
AMD는 첫 번째 AMD Instinct MI325X 제출과 파트너에 의한 첫 번째 다중 노드 MI300X 제출로 강력한 MLPerf Inference v5.0 결과를 발표하게 되어 기쁩니다. 이번 라운드는 AMD의 AI 확장성, 성능, 소프트웨어 발전 및 오픈소스 전략에 대한 투자를 강조하며, 다수의 파트너 제출을 통해 강력한 업계 채택을 보여줍니다.
처음으로, 여러 파트너—Supermicro(SMC), ASUSTeK, MI325X를 사용한 Giga Computing, 그리고 MI300X를 사용한 MangoBoost—가 AMD Instinct 솔루션을 사용하여 MLPerf 결과를 제출했습니다. Llama 2 70B에 대한 MI325X 파트너 제출은 AMD 자체 결과와 비슷한 성능을 달성했으며, 이는 다양한 환경에서 GPU의 일관성과 신뢰성을 강화합니다.
AMD는 또한 생성형 AI 워크로드에서 경쟁력 있는 성능을 보여주는 MI325X로 Stable Diffusion XL(SDXL)을 제출하여 MLPerf 벤치마크를 확장했습니다. 혁신적인 GPU 파티셔닝 기술이 SDXL 추론 성능 최적화에 중요한 역할을 했습니다.
MangoBoost는 AMD Instinct GPU를 사용하여 첫 다중 노드 MLPerf 제출을 달성했으며, 4개 노드의 MI300X GPU를 활용했습니다. 이 이정표는 대규모 AI 워크로드에 대한 AMD Instinct의 확장성과 효율성을 보여줍니다. 또한 지난 라운드의 8-GPU MI300X 제출에서 4 노드 32-GPU MI300X 제출로의 유의미한 확장을 보여주었으며, 다중 노드 배포에서 AMD 솔루션의 견고함을 더욱 강화했습니다.
MI300X에서 MI325X로의 전환은 빠른 하드웨어 및 소프트웨어 혁신으로 가능해진 Llama 2 70B 추론에서 상당한 성능 향상을 제공했습니다.
Broadcom
Broadcom은 AI와 ML의 비즈니스 이점과 조직의 개인정보 보호 및 규정 준수 요구 사항 사이의 균형을 맞추는 아키텍처 접근 방식으로 VMware Private AI를 선도하고 있습니다. VMware Cloud Foundation(VCF) 프라이빗 클라우드 플랫폼을 기반으로 구축된 이 접근 방식은 데이터의 개인정보 보호와 제어, 오픈소스 및 상용 AI 솔루션의 선택, 최적의 비용, 성능, 규정 준수, 최고 수준의 자동화 및 부하 균형을 보장합니다.
Broadcom은 가상화된 NVIDIA GPU의 힘을 VCF 프라이빗 클라우드 플랫폼에 제공하여 AI 가속 데이터 센터의 관리를 단순화하고 까다로운 AI 및 ML 워크로드에 대한 효율적인 애플리케이션 개발 및 실행을 가능하게 합니다. VMware 소프트웨어는 다양한 하드웨어 공급업체를 지원하여 확장 가능한 배포를 촉진합니다.
Broadcom은 NVIDIA, Supermicro 및 Dell Technologies와 협력하여 가상화의 이점을 보여주고 MLPerf Inference v5.0에서 인상적인 결과를 달성했습니다. 우리는 컴퓨터 비전, 의료 영상 및 60억 파라미터 GPT-J 언어 모델을 사용한 자연어 처리와 같은 다양한 AI 영역에서 거의 베어 메탈 수준의 성능을 입증했습니다. 또한 Mixtral-8x7B 560억 파라미터 대규모 언어 모델(LLM)로 뛰어난 결과를 달성했습니다. 아래 그래프는 가상화된 성능과 베어 메탈 성능을 비교한 것으로, NVIDIA 가상화된 GPU가 있는 vSphere 8.0.3의 오버헤드가 최소임을 보여줍니다. 초당 쿼리 또는 초당 토큰의 원시 비교는 공식 MLCommons Inference 5.0 결과를 참조하세요.
우리는 SuperMicro GPU SuperServer SYS-821GE-TNRT 및 Dell PowerEdge XE9680에서 8개의 가상화된 NVIDIA SXM H100 80GB GPU에서 MLPerf Inference v5.0을 실행했습니다. 이 VM은 사용 가능한 리소스의 일부만 사용했습니다—예를 들어, CPU 코어의 25%만 사용하고 나머지 75%는 다른 워크로드를 위해 남겨두었습니다. 이 효율적인 활용은 다른 애플리케이션의 동시 실행을 허용하면서 하드웨어 투자를 최대화합니다. 이는 AI/ML 인프라에 상당한 비용 절감으로 이어지며 동시에 vSphere의 강력한
데이터 센터 관리를 활용합니다. 이제 기업은 고성능 GPU와 vSphere의 운영 효율성을 모두 얻을 수 있습니다.
cTuning
cTuning Foundation은 컴퓨터 시스템 및 기계 학습 분야에서 오픈 소스, 협업 및 재현 가능한 연구를 발전시키기 위한 비영리 단체입니다. 성능 최적화 자동화, 실험 공유 촉진, 연구 워크플로우에서 재현성 향상을 위한 도구와 방법론을 개발합니다.
cTuning은 MLPerf 자동화와 함께 MLCommons CM 워크플로우 자동화 프레임워크로 구동되는 오픈 Collective Knowledge 플랫폼 개발을 주도합니다. 이 교육 이니셔티브는 사용자가 MLPerf 방법론 및 도구를 기반으로 다양한 모델, 데이터셋, 소프트웨어 및 하드웨어에서 AI, ML 및 기타 새로운 워크로드를 가장 효율적이고 비용 효과적인 방식으로 실행하는 방법을 배우는 데 도움을 줍니다.
이번 제출 라운드에서, 우리는 ACM, MLCommons 및 오픈 최적화 챌린지에 참여한 자원 봉사자 및 참가자와 협력하여 개발된 Collective Mind 프레임워크(CMX) 및 MLPerf 자동화의 새로운 프로토타입과 함께 Collective Knowledge 플랫폼을 테스트하고 있습니다.
자세한 내용은 다음을 방문하세요:
- https://github.com/mlcommons/ck
- https://access.cKnowledge.org
Cisco Systems Inc.
생성형 AI가 전 세계 경제 생산량을 크게 증가시킬 태세를 갖추면서, Cisco는 조직의 인프라를 AI 구현을 위해 준비하는 과제를 단순화하는 데 도움을 주고 있습니다. AI의 기하급수적인 성장은 데이터 센터 요구 사항을 변화시키고, 확장 가능한 가속 컴퓨팅 인프라에 대한 수요를 촉진하고 있습니다.
이를 위해 Cisco는 최근 까다로운 AI 워크로드를 위해 설계된 고밀도 GPU 서버인 Cisco UCS C885A M8을 도입했으며, 모델 훈련, 딥 러닝 및 추론을 위한 강력한 성능을 제공합니다. NVIDIA HGX 플랫폼을 기반으로 구축되어 가장 야심찬 AI 프로젝트에 생명을 불어넣는 컴퓨팅 파워 클러스터를 제공하도록 확장할 수 있습니다. 각 서버에는 AI 네트워킹 성능을 가속화하는 NVIDIA NIC 또는 SuperNIC와 함께 GPU 데이터 접근을 가속화하고 강력한 제로 트러스트 보안을 가능하게 하는 NVIDIA BlueField-3 DPU가 포함되어 있습니다. 새로운 Cisco UCS C885A M8은 Cisco의 전용 AI 서버 포트폴리오 중 첫 번째이자 NVIDIA HGX 플랫폼을 기반으로 한 첫 8웨이 가속 컴퓨팅 시스템입니다.
Cisco는 Intel 및 NVIDIA와 협력하여 성능 및 효율성을 향상시키기 위해 MLPerf v5.0 Inference 결과를 성공적으로 제출했으며, 대규모 언어 모델(언어), 자연어 처리(언어), 이미지 생성(이미지), 생성형 이미지(텍스트에서 이미지), 이미지 분류(비전), 객체 탐지(비전), 의료 영상 분할(비전) 및 추천(상업) 등 다양한 추론 워크로드를 최적화했습니다.
Cisco UCS 플랫폼 전반의 뛰어난 AI 성능:
- 8개의 NVIDIA H200 SXM GPU가 장착된 Cisco UCS C885A M8 플랫폼
- 8개의 NVIDIA H100 SXM GPU가 장착된 Cisco UCS C885A M8 플랫폼
- 2개의 NVIDIA PCIe H100-NVL GPU 및 2개의 NVIDIA PCIe L40S GPU가 장착된 Cisco UCS C245 M8, X215 M8 + X440p PCIe 노드
- Intel Granite Rapid 6787P 프로세서가 장착된 Cisco UCS C240 M8
CoreWeave
CoreWeave는 오늘 AI 추론에서 뛰어난 성능 벤치마크를 설정한 MLPerf Inference v5.0 결과를 발표했습니다. CoreWeave는 NVIDIA GB200 GPU를 사용하여 결과를 제출한 최초의 클라우드 제공업체입니다.
두 개의 Grace CPU와 네 개의 Blackwell GPU를 갖춘 CoreWeave GB200 인스턴스를 사용하여 CoreWeave는 오픈 소스 모델 중 가장 큰 모델 중 하나인 Llama 3.1 405B 모델에서 초당 800 토큰(TPS)을 제공했습니다. CoreWeave는 또한 NVIDIA H200 GPU 인스턴스에 대한 결과를 제출하여 Llama 2 70B 모델 벤치마크에서 초당 33,000개 이상의 TPS를 달성했습니다.
"CoreWeave는 목적에 맞게 구축된 클라우드 플랫폼을 통해 대규모 모델 추론에 최적화된 최첨단 인프라를 제공하기 위해 노력하고 있습니다," CoreWeave의 최고 기술 책임자인 Peter Salanki는 말했습니다. "이러한 벤치마크 MLPerf 결과는 CoreWeave가 일부 주요 AI 연구소 및 기업에서 선호하는 클라우드 제공업체로서의 위치를 강화합니다."
CoreWeave는 완전 통합된 목적 구축 클라우드 플랫폼을 통해 성능 향상을 제공합니다. 우리의 베어 메탈 인스턴스는 NVIDIA GB200 및 H200 GPU, 고성능 CPU, Quantum 스위치가 있는 NVIDIA InfiniBand, 그리고 모든 노드가 최대 효율로 실행되도록 돕는 Mission Control을 갖추고 있습니다.
올해 CoreWeave는 NVIDIA GB200 NVL72 인스턴스를 일반적으로 제공한 최초의 회사가 되었습니다. 작년에는 NVIDIA H100 및 H200 GPU를 제공한 최초의 회사 중 하나였으며 GB200을 데모한 최초의 회사 중 하나였습니다.
Dell Technologies
Dell은 NVIDIA, Intel 및 Broadcom과 협력하여 다양한 가속기 및 아키텍처에 걸쳐 업계 최고의 AI 추론 성능을 보여주는 획기적인 MLPerf Inference v5.0 결과를 제공했습니다.
주력 플랫폼 전반의 타의 추종을 불허하는 AI 성능:
- PowerEdge XE9680 및 XE9680L(수냉식): 이 주력 AI 추론 서버는 NVIDIA H100 및 H200 SXM GPU를 포함한 고성능 가속기를 지원하여 까다로운 ML 워크로드에 대한 타의 추종을 불허하는 유연성과 컴퓨팅 파워를 보장합니다.
- PowerEdge XE7745: 8개의 NVIDIA H200-NVL 또는 8개의 L40S GPU를 갖춘 이 PCIe 기반 파워하우스는 뛰어난 성능과 업계 최고의 와트당 성능 효율성을 보여주어 더 낮은 에너지 비용으로 AI 확장을 위한 강력한 경쟁자가 되었습니다.
실제 LLM 추론에서의 획기적인 결과:
- 모델 크기별 우수한 성능: Dell의 MLPerf 제출에는 소형(GPT-J 6B), 중형(Llama 2 70B) 및 대형(Llama 3 405B) LLM에 걸친 결과가 포함되어 있어 다양한 AI 워크로드에서 일관된 효율성과 가속을 강조합니다.
- 지연 시간에 민감한 AI에 최적화: MLCommon은 실시간에서 어떻게 작동하는지 보여주기 위해 Llama 2 70B-Interactive 모델을 추가했습니다. 우리는 얼마나 잘 수행되는지 보여주기 위해 데이터를 공유했습니다.
더 똑똑한 AI 인프라 결정을 위한 데이터 기반 성능 통찰:
에너지 효율적이고 고성능이며 지연 시간이 최적화된 AI 추론 솔루션을 제공함으로써 Dell은 차세대 ML 배포의 벤치마크를 설정하여 조직이 자신있게 AI 채택을 가속화할 수 있도록 지원합니다. 강력한 Dell Technologies 솔루션으로 더 높은 품질, 더 빠른 예측 및 출력을 생성하면서 의사 결정을 가속화하세요. 전 세계 고객 솔루션 센터에서 테스트 드라이브하거나 혁신 연구소에서 협력하여 엑셀런스 센터의 전문성을 활용하세요.
FlexAI
FlexAI는 Apple, Intel, NVIDIA 및 Tesla 출신의 업계 베테랑들이 설립한 파리 기반 회사입니다. Workload as a Service(WaaS) 플랫폼을 통해 AI 워크로드를 최적화하고 단순화하는 데 특화되어 있습니다. 이 플랫폼은 동적으로 확장, 적응 및 자가 복구하여 개발자가 AI 모델을 더 빠르게, 더 낮은 비용으로, 그리고 복잡성을 줄여 훈련, 미세 조정 및 배포할 수 있도록 합니다.
이번 제출 라운드에서 FlexAI는 커뮤니티와 함께 MLPerf LoadGen을 기반으로 한 간단한 오픈 소스 도구의 프로토타입을 공유했습니다. 이 도구는 vLLM 및 기타 추론 엔진을 사용하여 일반 소프트웨어 및 하드웨어 스택에서 Hugging Face Hub의 비-MLPerf 모델 및 데이터셋의 기본 성능과 정확도를 벤치마킹합니다.
우리는 DeepSeek R1 및 Llama 3.3 모델로 오픈 제출에서 이 프로토타입을 검증했습니다. 이 도구의 전체 자동화 및 최적화 워크플로우가 포함된 고급 버전은 FlexAI 클라우드에서 사용할 수 있습니다. 자세한 내용은 다음을 방문하세요: https://flex.ai
Fujitsu
Fujitsu는 최대 생산성, 효율성 및 유연성을 보장하는 시스템, 솔루션 및 전문 지식의 환상적인 조합을 제공하여 신뢰성과 신뢰성을 제공합니다. 2020년부터 데이터 센터와 엣지 부문 모두에 대한 추론 및 훈련 라운드에 적극적으로 참여하고 제출해 왔습니다.
이번 라운드에서는 PCIe Gen.5와 호환되는 외부 박스가 있는 PRIMERGY CDI에 초점을 맞추었으며, 8개의 H100 NVL GPU를 갖추고 있어 데이터 센터 클로즈드 부문과 그 전력 부문 두 가지 부문을 제출했습니다.
PRIMERGY CDI는 컴퓨팅 서버, PCIe 패브릭 스위치 및 PCIe 박스로 구성된 전통적인 서버 제품과 차별화됩니다. GPU, SSD 및 NIC와 같은 장치 리소스는 컴퓨팅 서버 섀시 내부가 아닌 PCIe 박스 외부에 저장됩니다. PRIMERGY CDI의 가장 주목할만한 특징은 PCIe 박스 내의 장치를 여러 컴퓨팅 서버에 자유롭게 할당할 수 있다는 것입니다. 예를 들어, 낮에는 추론 작업을 위한 GPU 수를 줄이고 밤에는 훈련 작업을 위해 증가시킬 수 있습니다. 이러한 GPU 할당의 유연성은 특정 워크로드에 대한 GPU를 점유하지 않고도 서버 대기 전력을 줄일 수 있게 합니다.
이번 라운드에서 8개의 H100 NVL GPU를 장착한 PRIMERGY CDI 시스템은 이전 라운드에서 제출할 수 없었던 mixtral-8x7b뿐만 아니라 새로 추가된 llama 2 70b-interactive 및 RGAT를 포함한 7개의 벤치마크 프로그램 전반에서 뛰어난 결과를 달성했습니다.
우리의 목적은 혁신을 통해 사회에 신뢰를 구축함으로써 세계를 더 지속 가능하게 만드는 것입니다. 혁신과 전문성을 주도하는 풍부한 유산을 갖춘 우리는 사회와 소중한 고객의 성장에 기여하기 위해 최선을 다하고 있습니다. 따라서 우리는 계속해서 고객의 요구를 충족시키고 MLCommons의 활동을 통해 매력적인 서버 시스템을 제공하기 위해 노력할 것입니다.
GATEOverflow
인도에 기반을 둔 교육 이니셔티브인 GATEOverflow는 기계 학습 벤치마킹에 있어 지속적인 노력을 반영하는 첫 번째 MLPerf Inference v5.0 제출을 발표하게 되어 기쁩니다. 이 제출은 GO Classes의 지원을 받아 학생들의 적극적인 참여로 진행되었으며, 실제 ML 성능 평가에 대한 실습 경험을 촉진했습니다.
우리의 결과—15,000개 이상의 성능 벤치마크—는 MLCommons의 자동화 프레임워크인 MLCFlow를 사용하여 생성되었으며, 노트북, 워크스테이션, AWS, GCP 및 Azure와 같은 클라우드 플랫폼을 포함한 다양한 하드웨어에 배포되었습니다.
주목할 만한 것은 GATEOverflow가 모든 클로즈드 엣지 제출 중 80% 이상을 기여했다는 점입니다. 우리는 또한 엣지 카테고리에서 유일한 전력 제출자이며 새롭게 도입된 PointPainting 모델에 대한 유일한 제출자입니다.
이 제출은 오픈, 투명하고 재현 가능한 벤치마킹에 대한 GATEOverow의 헌신을 강조합니다. MLCFlow 자동화 개발과 이 제출의 성공에 역할을 한 모든 참가자와 기여자에게 감사드립니다. 이 성과로 우리는 AI 벤치마킹의 추가 혁신과 MLPerf 커뮤니티 내에서 협력을 확대하기를 기대합니다.
Giga Computing
GIGABYTE 자회사인 Giga Computing은 서버 하드웨어 및 고급 냉각 솔루션을 전문으로 합니다. 독립적으로 운영되며, 데이터 센터, 엣지 환경, HPC, AI, 데이터 분석, 5G 및 클라우드를 위한 고성능 컴퓨팅을 제공합니다. 강력한 업계 파트너십을 통해 성능, 보안, 확장성 및 지속 가능성 분야의 혁신을 주도합니다. Giga Computing은 박람회에서 GIGABYTE 배너 아래 참여하면서 널리 알려진 GIGABYTE 브랜드를 활용합니다.
MLCommons의 창립 멤버로서 Giga Computing은 AI 훈련 및 추론 워크로드를 위한 서버 솔루션 벤치마킹에 있어 커뮤니티의 노력을 계속 지원합니다. 최신 MLPerf Inference v5.0 벤치마크에서 Giga Computing은 AMD Instinct TM MI325X 및 NVIDIA HGX TM H200를 포함한 가장 고급 가속기를 장착한 GIGABYTE G893 공랭식 시리즈를 기반으로 테스트 결과를 제출했습니다. 이 시스템은 업계 최고의 성능을 보여주며 모든 주류 AI 플랫폼에 걸쳐 포괄적인 테스트 결과를 제공합니다.
이 시스템은 높은 데이터 대역폭, 큰 메모리 용량, 최적화된 GPU 리소스 할당, 그리고 InfiniBand, Infinity Fabric 및 모든 이더넷 설계와 같은 고유한 데이터 전송 솔루션에서 뛰어납니다. 철저하게 최적화된 열 설계와 검증된 시스템으로, 우리의 결과는 자체적으로 말해줍니다—모든 벤치마크 작업에서 최고 수준의 성능을 유지하면서 뛰어난 효율성을 제공합니다.
Giga Computing에서 우리는 지속적인 개선에 전념하여 시스템 평가를 위한 원격 테스트 및 공개 벤치마크를 제공합니다. 우리는 또한 현대 컴퓨팅의 증가하는 전력 요구를 해결하기 위해 침수 및 직접 액체 냉각(DLC)을 포함한 고급 냉각 기술 분야를 선도하고 있습니다. Giga Computing과 함께 컴퓨팅 우수성의 경계를 넓혀 나가는 모습을 지켜봐 주세요.
Google Cloud
MLPerf Inference v5.0에서 Google Cloud는 A3 Ultra(NVIDIA H200) 및 A4(NVIDIA HGX B200) VM과의 첫 제출을 포함하여 15개의 결과를 제출했으며, 6세대 TPU인 Trillium의 두 번째 제출을 했습니다. 강력한 결과는 생산성과 효율성을 향상시키기 위해 AI 최적화 하드웨어, 소프트웨어 및 소비 모델을 결합한 AI Hypercomputer의 성능을 보여줍니다.
A3 Ultra VM은 8개의 NVIDIA H200 Tensor Core GPU로 구동되며 3.2 Tbps의 GPU-to-GPU 논블로킹 네트워크 대역폭과 NVIDIA H100 GPU가 있는 A3 Mega에 비해 두 배의 고대역폭 메모리(HBM)를 제공합니다. Google Cloud의 A3 Ultra는 LLM, MoE, 이미지 및 추천 모델 전반에 걸쳐 매우 경쟁력 있는 성능을 보여주었습니다. 또한, 미리보기 중인 A4 VM은 NVIDIA HGX B200 GPU로 구동되어 비교 가능한 GPU 제출 중에서 두드러진 결과를 달성했습니다. A3 Ultra 및 A4 VM은 가장 까다로운 AI 워크로드를 위한 인프라를 제공하기 위한 Google Cloud와 NVIDIA 간의 지속적인 긴밀한 파트너십의 증거인 강력한 추론 성능을 제공합니다.
Google Cloud의 Trillium, 6세대 TPU는 지금까지 가장 높은 추론 성능을 제공합니다. Trillium은 이미지 생성과 같은 컴퓨팅 집약적 워크로드에서 계속해서 뛰어난 성능을 발휘하며, MLPerf v4.1 제출 이후 Stable Diffusion XL(SDXL) 처리량을 12% 더 향상시켰습니다. Trillium은 이제 이전 라운드에서 전임자인 TPU v5e가 보여준 성능에 비해 SDXL에 대한 초당 쿼리/초당 처리량이 3.5배 향상되었습니다. 이는 Trillium의 목적에 맞게 설계된 아키텍처와 증가된 컴퓨팅 파워를 활용하기 위한 추론 프레임워크, 특히 오픈 소프트웨어 스택의 발전 덕분입니다.
Hewlett Packard Enterprise
이것은 Hewlett Packard Enterprise(HPE)가 v1.0 이후 참여한 8번째 라운드이며, 고성능 서버, 스토리지 및 네트워킹 제품 포트폴리오는 일관되게 강력한 AI 추론 결과를 보여주었습니다. 이번 라운드에서 HPE는 파트너인 NVIDIA와 함께 Compute 및 고성능 컴퓨팅(HPC) 서버 제품군에서 여러 새로운 구성을 제출했습니다.
HPE ProLiant Compute Gen12 포트폴리오는 다양한 AI 모델과 추론 예산을 지원하기 위해 성능과 효율성에 최적화된 서버를 제공합니다. 주요 내용은 다음과 같습니다:
- HPE ProLiant Compute DL380a Gen12 – 서버당 8개의 NVIDIA H200 NVL, H100 NVL 또는 L40S GPU를 지원 – 및 NVIDIA TensorRT LLM은 업그레이드 및 성능 최적화 덕분에 지난 라운드 이후 추론 처리량이 두 배 이상 증가했습니다.
- 듀얼 소켓(2P) NVIDIA GH200 144GB가 장착된 HPE ProLiant Compute DL384 Gen12는 HPE의 MLPerf 결과에서 중요한 첫 번째로, 싱글 소켓(1P) NVIDIA GH200 144GB 제출보다 두 배의 성능을 보여주었습니다.
HPE Cray XD 포트폴리오는 다양한 훈련 및 추론 사용 사례에 대한 고성능을 제공합니다. 추론 결과에 대한 주요 내용은 다음과 같습니다:
- 8-GPU NVIDIA HGX H200 및 H100 베이스보드가 있는 HPE Cray XD670 공랭식 서버는 지금까지 가장 높은 MLPerf 추론 성능을 제공했습니다.
- 모든 HPE Cray 결과는 데이터셋과 모델 체크포인트를 호스팅하기 위해 HPE GreenLake for File Storage 또는 HPE Cray ClusterStor E1000 스토리지 시스템을 사용했으며, 데이터셋과 체크포인트를 로컬 디스크로 이동시키지 않고도 높은 처리량 추론을 얻을 수 있음을 증명했습니다.
HPE는 MLCommons 커뮤니티와 파트너들이 지속적인 혁신과 MLPerf를 AI 성능을 측정하는 업계 표준으로 만든 것에 감사드립니다.
Intel
최신 MLPerf Inference v5.0 결과는 Intel Xeon 6 with P-cores가 AI 추론 및 범용 AI 워크로드에서 강점을 재확인합니다.
6개의 MLPerf 벤치마크에서 Xeon 6 CPU는 이전 세대인 5세대 Intel Xeon 프로세서보다 1.9배 향상된 AI 성능 향상을 제공했습니다. 이 결과는 고전적 기계 학습, 소형에서 중간 크기 모델, 관계형 그래프 노드 분류를 포함한 AI 워크로드에서 Xeon의 능력을 강조합니다.
2021년 처음으로 Xeon을 MLPerf에 제출한 이후(3세대 Intel Xeon Scalable Processors 사용), Intel은 하드웨어 및 소프트웨어 발전으로 인해 최대 15배의 성능 향상을 달성했으며, 최근 최적화로 v4.1보다 22% 결과가 향상되었습니다.
특히, Intel은 MLPerf에 서버 CPU 결과를 제출하는 유일한 공급업체입니다. 그리고 Xeon은 계속해서 가속 시스템의 선택 호스트 CPU로 남아 있습니다.
Intel은 또한 여러 고객의 제출을 지원했으며 OEM 파트너 - Cisco, Dell Technologies, Quanta 및 Supermicro - 와 협력하여 Intel Xeon 6 with P-cores로 구동되는 MLPerf 제출을 제공했습니다. 측정 및 책임성에 대한 신뢰할 수 있는 표준을 만들어 주신 MLCommons에 감사드립니다. 자세한 내용은 MLCommons.org를 참조하세요.
KRAI
2020년 영국 캠브리지("The Silicon Fen")에 설립된 KRAI는 AI 시스템을 위한 프리미엄 벤치마킹 및 최적화 솔루션을 제공합니다. 우리의 경험 많은 팀은 11번의 MLPerf Inference 라운드 중 11번 모두 참여했으며, 주요 공급업체와 협력하여 MLPerf 역사상 가장 빠르고 에너지 효율적인 결과 중 일부에 기여했습니다.
우리는 매우 경쟁력 있고 완전히 준수하는 MLPerf 제출을 준비하는 데 얼마나 많은 노력(몇 개월에서 몇 년)이 들어가는지 직접 알기 때문에, 더 현실적인 노력(며칠에서 몇 주)으로 무엇을 달성할 수 있는지 보여주려고 했습니다. 최첨단 DeepSeek-v3-671B 오픈 디비전 워크로드의 유일한 제출자로서, 우리는 8개의 MI300X-192GB GPU에서 Llama 3.1 405B와 비교했습니다. 놀랍게도, (희소) DeepSeek-v3는 초당 토큰(TPS: 243.45 대 278.65) 측면에서 (밀집) Llama 3.1 405B보다 느렸을 뿐만 아니라, 덜 정확했습니다(예: rougeL: 18.95 대 21.63).
또한, 우리는 8개의 H200-141GB GPU에서 여러 공개 Docker 이미지를 사용하여 Llama 3.1 70B의 성능을 비교했으며, NIM v1.5.0으로 최대 30,530 TPS, SGLang v0.4.3으로 27,950 TPS, 그리고 vLLM v0.6.4로 21,372 TPS의 오프라인 점수를 달성했습니다. 흥미롭게도, NIM은 초당 쿼리(QPS: 94.26 대 95.65) 측면에서 SGLang보다 느렸습니다. 이는 NIM이 SGLang보다 덜 정확하면서도(예: rouge1: 46.52 대 47.57), 샘플당 평균적으로 더 많은 토큰을 생성했기 때문입니다. 훨씬 더 엄격한 지연 시간 제약이 있는 새로운 인터랙티브 서버 카테고리에서, NIM은 비인터랙티브 서버의 28,421 TPS와 오프라인의 30,530 TPS에 비해 15,960 TPS를 달성했습니다.
8개의 NVIDIA H200 GPU가 있는 Cray XD670 서버에 대한 접근을 제공해 주신 Hewlett Packard Enterprise와 8개의 AMD MI300X GPU가 있는 PowerEdge XE9680 서버에 대한 접근을 제공해 주신 Dell Technologies에 진심으로 감사드립니다.
Lambda
Lambda 소개
Lambda는 세계 최고의 기계 학습 컨퍼런스에서 발표된 연구를 가진 AI 엔지니어들에 의해 2012년에 설립되었습니다. 우리의 목표는 전체 AI 개발 수명 주기에 걸쳐 개발자들을 지원하는 #1 AI 컴퓨트 플랫폼이 되는 것입니다. Lambda는 AI 엔지니어들이 규모에 맞게 AI 제품을 쉽게, 안전하게, 그리고 저렴하게 구축, 테스트 및 배포할 수 있도록 합니다. 우리의 제품 포트폴리오는 온프레미스 GPU 하드웨어부터 클라우드의 호스팅 GPU까지 - 공용 및 비공개 환경 모두에서 - 다양합니다. Lambda의 사명은 전기처럼 계산에 대한 접근이 쉽고 보편적인 세상을 만드는 것입니다.
벤치마크에 대하여
이번이 NVIDIA와 파트너십으로 우리 팀이 처음으로 MLPerf 추론 라운드에 참여하는 것입니다. 우리의 벤치마크는 두 개의 Lambda Cloud 1-Click