AI가 과학 분야의 중심으로 부상: ISC2025 개막 기조연설

ISC는 전통적으로 고성능 컴퓨팅(HPC) 컨퍼런스였지만, 올해 개막 기조연설에서는 AI가 과학적 발견의 미래에 중심적인 역할을 하고 있음이 명확히 드러났습니다. AMD와 오크리지 연구소의 리더들은 AI와 HPC가 어떻게 융합하여 양자 화학부터 차세대 항공기 엔진까지 혁신적인 연구를 가능하게 하는지, 그리고 에너지 효율성, 메모리 대역폭, 아키텍처 유연성이 미래에 무엇이 가능할지 결정하는 요소임을 설명했습니다.
---
AMD의 CTO인 Mark Papermaster와 국립 컴퓨팅 과학 센터 및 오크리지 리더십 컴퓨팅 시설(OLCF)의 CTO인 Scott Atchley가 발표한 ISC2025 개막 기조연설은 HPC-AI 기술이 과학을 어떻게 발전시키는지 보여주는 훌륭한 그림과 함께, 이러한 성과와 미래 열망을 지원하기 위해 필요한 에너지 소비 문제에 대한 경각심을 불러일으켰습니다.
Papermaster는 현재 엑사스케일 시스템(El Capitan 및 Frontier)에서 AMD의 CPU-GPU 페어링의 성공을 강조했으며, 이번 주 후반에 최신 Instinct GPU인 MI350 시리즈를 소개할 것임을 예고했습니다.
"저는 수십 년 동안 이 기술 개발에 참여해 왔지만, AI는 정말로 혁신적인 기술, 혁신적인 애플리케이션이며, 이 커뮤니티가 수십 년 동안 추진해온 HPC와 과학 기술을 기반으로 한다는 데 동의하실 것입니다," Papermaster가 청중에게 말했습니다. "이러한 컴퓨팅 접근 방식은 절대적으로 얽혀 있으며, 우리는 AI와 그 새로운 애플리케이션이 우리가 하는 거의 모든 것을 어떻게 변화시킬 수 있는지 이제 막 보기 시작했습니다."

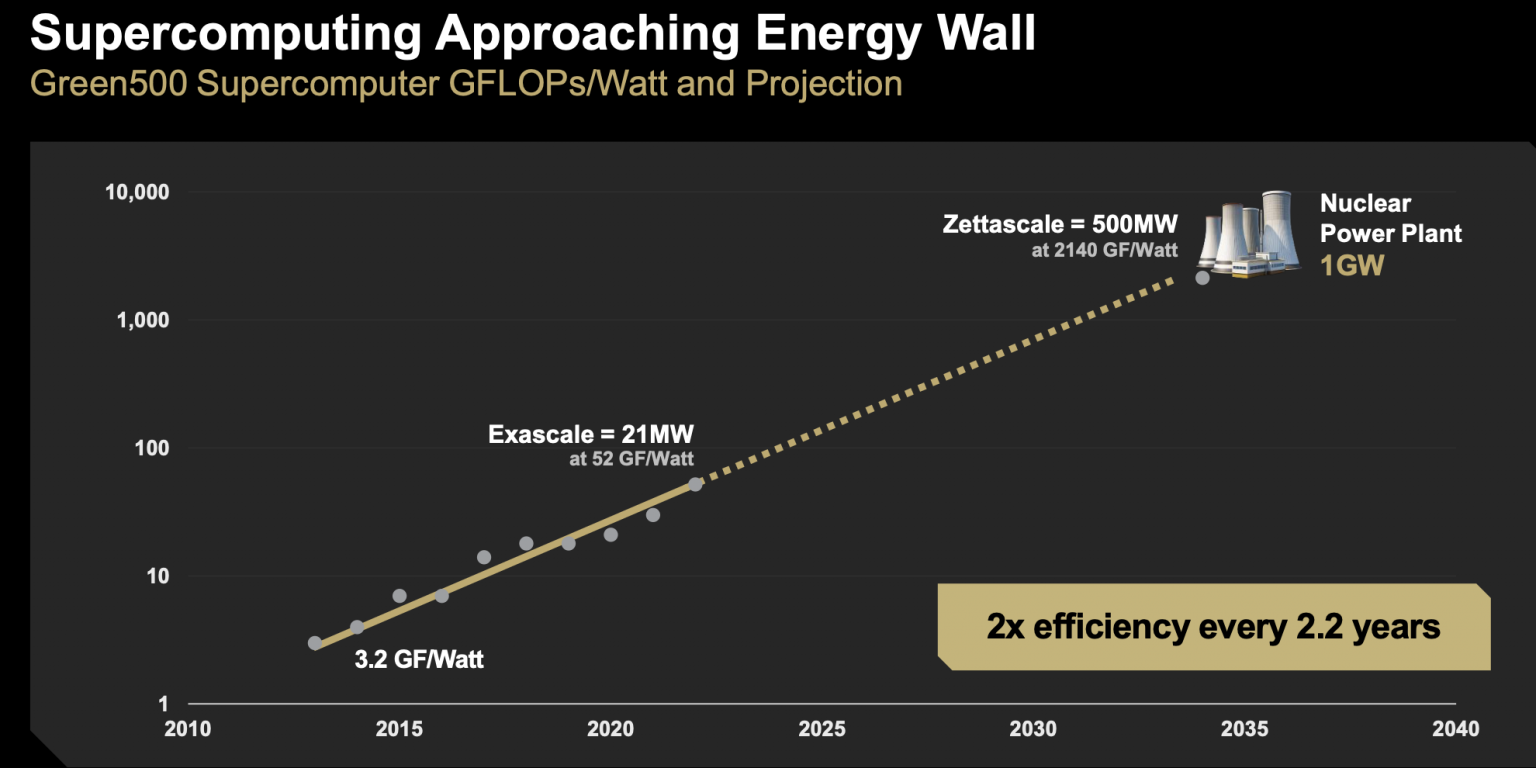
Papermaster의 발표는 낙관론이 넘쳤지만, 그는 무어의 법칙의 둔화를 인정하고 진전을 유지하기 위해서는 전체적인 설계 접근 방식이 필요하다고 주장했습니다.
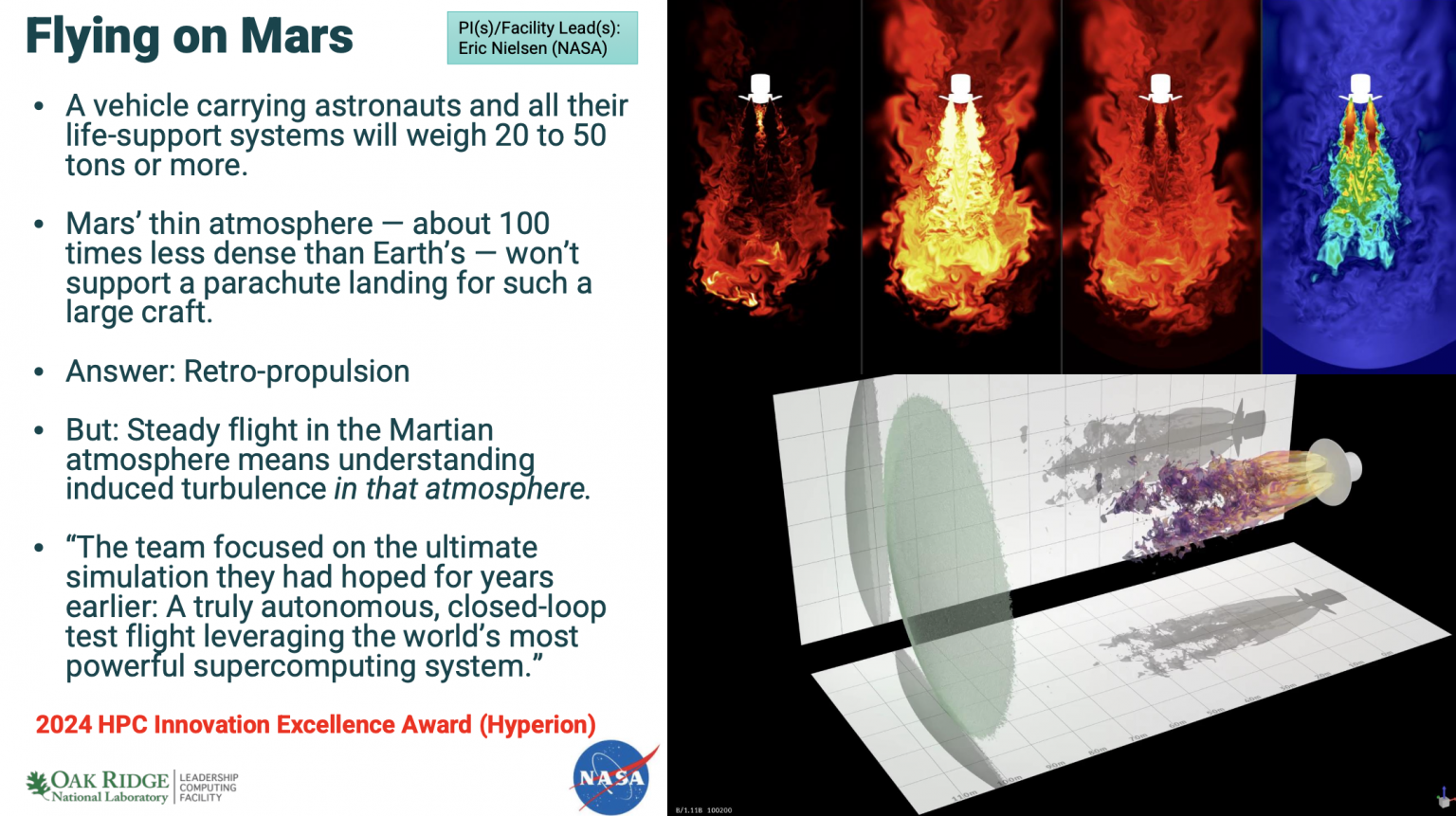
Atchley는 미국 에너지부 연구소 조직과 OLCF의 스냅샷을 제공하고, 엑사스케일 컴퓨팅(Frontier)으로 가능해진 과학의 예를 보여주었습니다. 그는 연료 효율적인 제트 엔진 개발, 화성 임무를 위한 역추진 시스템, 다이아몬드를 가장 단단한 형태의 탄소인 BC8로 전환하는 시뮬레이션, 약물 설계에 사용되는 양자 화학 계산 등을 살펴보았습니다. 마지막 예는 2024년 Gordon Bell Prize 수상작입니다.
그는 또한 DOE가 이미 AI를 적극적으로 사용하고 있으며, 과학 컴퓨팅의 융합은 양자 컴퓨팅 자원과 연결되는 노력을 인용하며 계속 성장할 것이라고 주장했습니다.
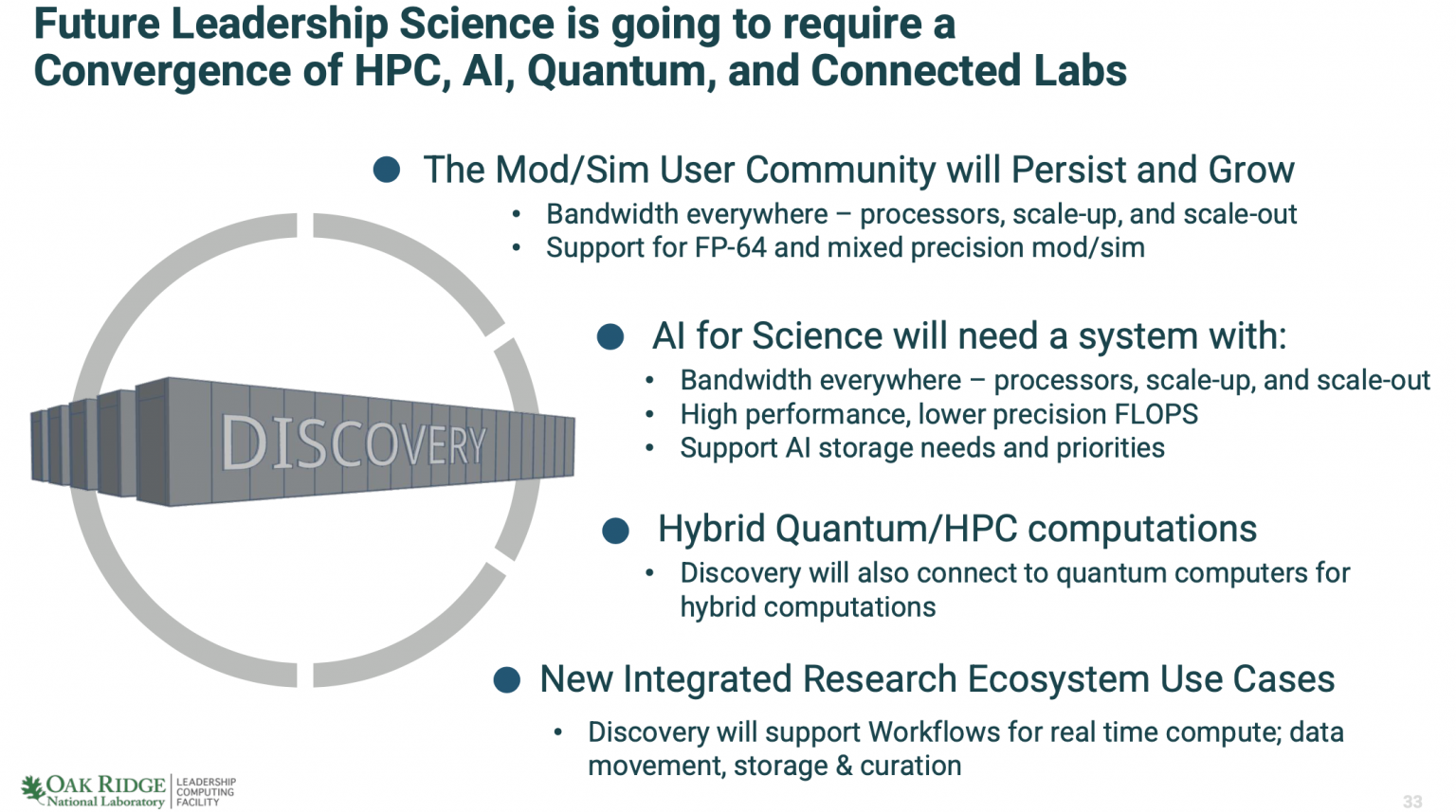
"OLCF와 Frontier에 대해 조금 말씀드리고, Frontier에서 수행하고 있는 과학, 그리고 그 이후에 무엇이 올 것인지에 대해 이야기하겠습니다. 오크리지 국립 연구소는 미국의 17개 국립 연구소 중 하나입니다. 컴퓨팅 측면에서 두 가지 다른 부서가 있습니다. NNSA(국가 핵 안보 관리국)가 핵무기 비축을 관리하고, 또 다른 하나는 오픈 사이언스 측면인데, 우리는 그곳에 있습니다. 우리는 국립 계산 과학 센터에 있으며, 오크리지 리더십 컴퓨팅 시설은 에너지부를 대신하여 이러한 대형 시스템을 운영합니다."라고 Atchley가 말했습니다.
"OLCF에는 2000명 이상의 사용자가 있습니다. 전 세계 25개국, 300개 이상의 기관에서 오며, 지난 5년간 175개 이상의 산업 파트너 프로젝트가 있었습니다. 사용자의 약 절반은 학계, 약 40%는 미국 연방 정부, 약 10%는 산업체에서 옵니다. 우리에게는 세 가지 대규모 할당 프로그램이 있습니다. 이들은 매우 경쟁적이며, 가장 큰 것은 INCITE로 우리 사이클의 약 60%를 할당합니다. 이는 리더십 프로그램으로, 이 프로그램을 통해 시간을 얻으려면 시스템의 최소 20%, 이상적으로는 전체 시스템을 사용할 수 있어야 합니다."라고 Atchley가 말했습니다.
ISC는 기조연설을 녹화했으며 연말까지 녹화본에 대한 접근을 유지할 것입니다.
Papermaster의 의견부터 시작하겠습니다. 그는 칩 설계, 혼합 정밀도 수학의 유연한 사용, 개방성(표준)의 필요성 등 광범위한 기술 문제를 다루었습니다. 그의 주제는 에너지 효율성을 포함한 효율성 증가, 전체적인 설계, 새로운 에너지원 개발의 필요성에 관한 것이었습니다. Papermaster는 용감하게(아마도) Zettascale을 언급하는 슬라이드도 보여주었지만, 그 목표는 여전히 멀어 보입니다.
칩 설계에 관해서 그는 TSMC의 2nm 제조 공정에서 나온 AMD의 첫 제품을 언급했습니다. "이것은 CPU 제품으로, 게이트 올 어라운드 기술이며, 와트당 계산 효율성이 탁월하지만, 이러한 새로운 노드는 훨씬 더 비싸고 제조하는 데 시간이 더 오래 걸립니다. 따라서 우리가 가졌던 종류의 패키징 혁신을 계속해야 하며, 광범위한 하드웨어/소프트웨어 공동 최적화에 계속 의존해야 합니다."라고 그는 말했습니다.
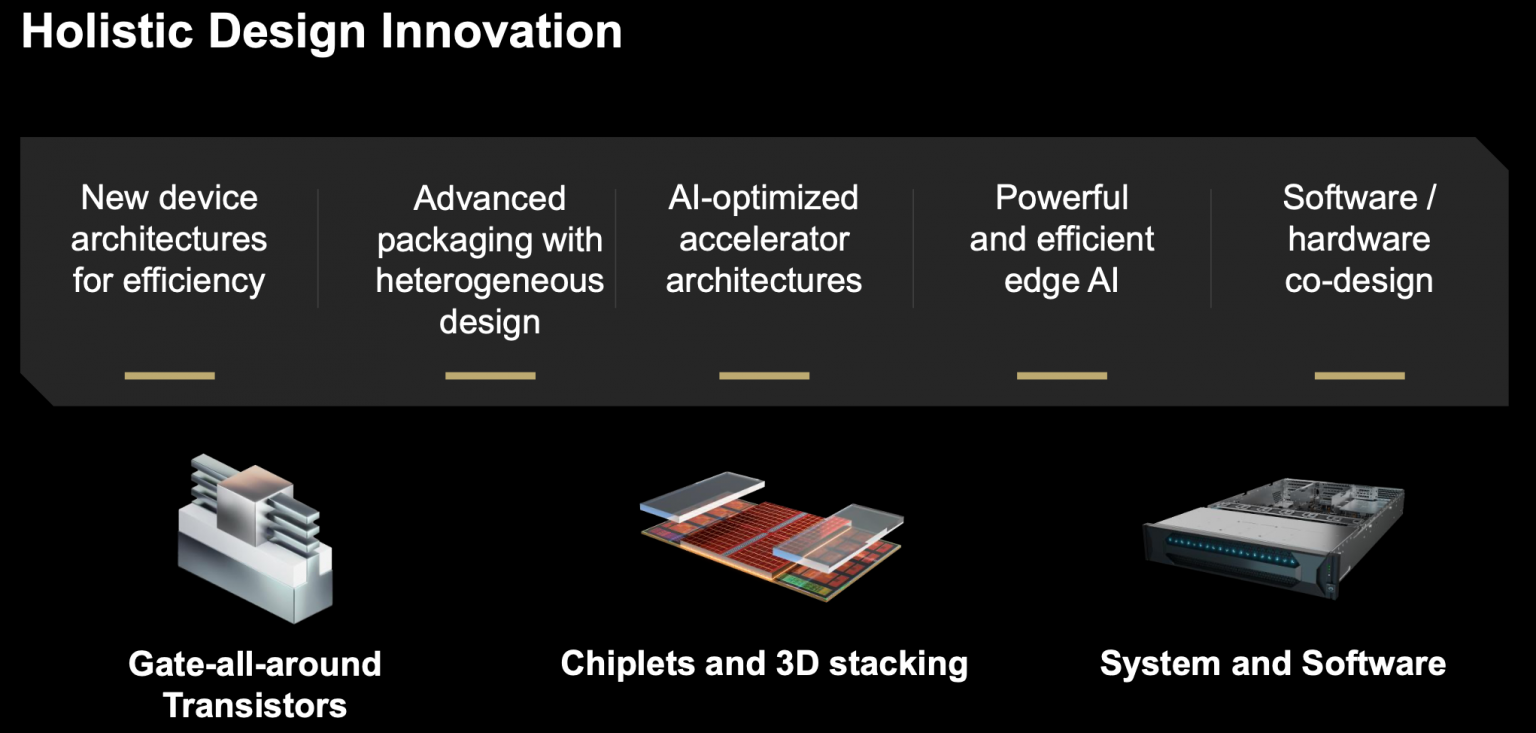
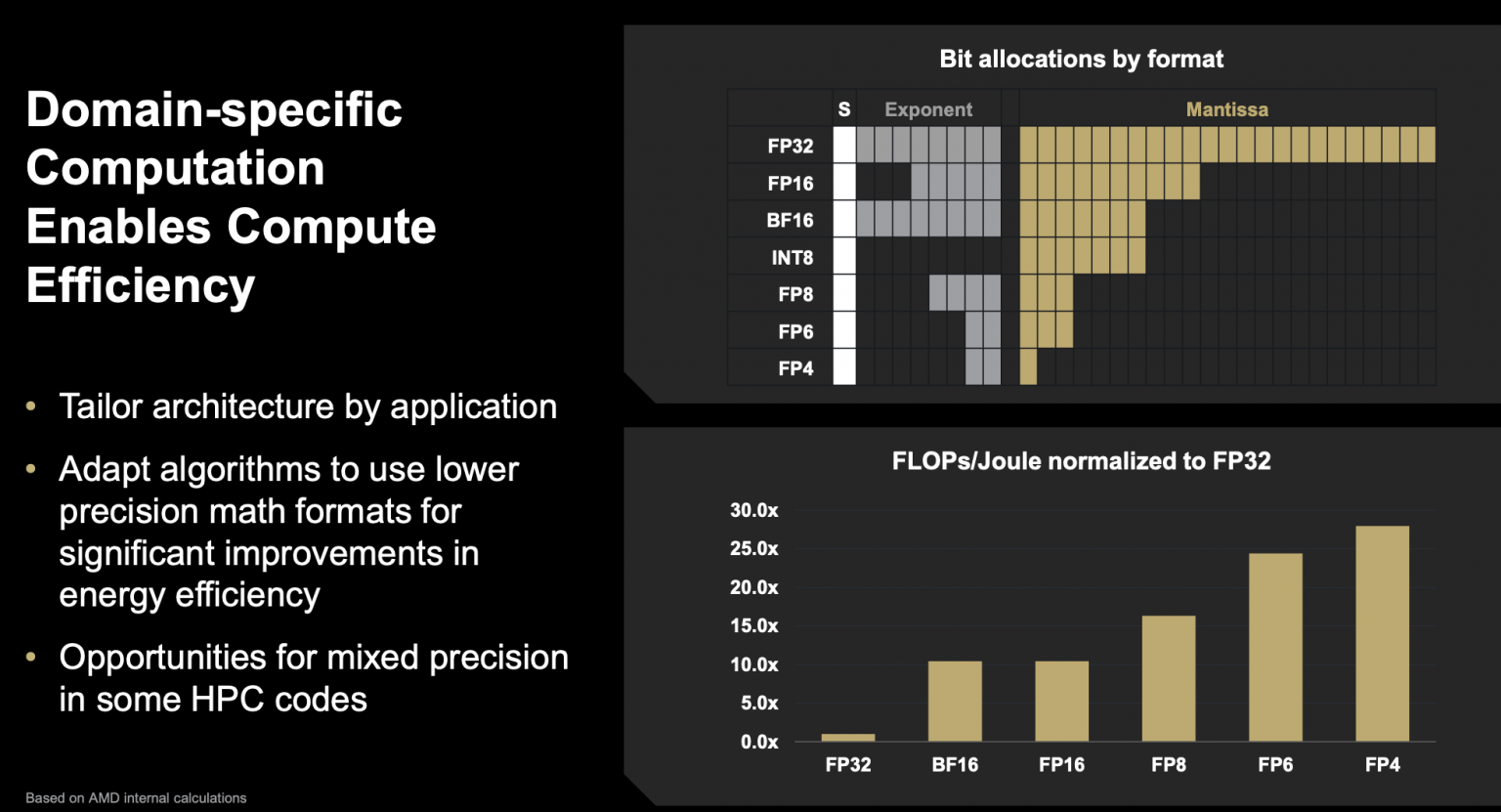
Papermaster는 이를 도메인 특화 계산이라고 부르며 다양한 혼합 정밀도 실행을 수용할 필요성을 강조했습니다.
그는 "분명히 IEEE 부동 소수점은 매우 뛰어나고 우리가 필요로 하는 정확성을 가지고 있습니다. 수년에 걸쳐 개발해 온 많은 소프트웨어 라이브러리가 있으며, 이는 사라지지 않을 것입니다. 하지만 오른쪽 상단(슬라이드)을 보면 더 많은 비트가 필요합니다. 따라서 모든 계산마다 처리하는 비트가 더 많으며, 아래쪽 곡선을 보면 정밀도를 줄일 수 있다면 효율성이 낮습니다." 정밀도를 줄여 적용할 수 있는 영역을 찾는 것이 시급합니다. "이는 극적인 계산 생산성 증가를 이끌어내며, 훨씬 더 높은 에너지 효율성으로 그렇게 합니다."

Papermaster는 GPU 사용 증가가 메모리에 추가 부담을 주며 개선된 지역성의 필요성을 강조한다고 언급했습니다. 하지만 그것이 정확히 무엇을 의미하는지는 항상 명확하지 않습니다.
"GPU 계산의 일부, 즉 HPC와 AI 전반에 걸쳐 구동하는 병렬 계산에 대해 생각해보면, 우리는 실제로 2년마다 GPU 플롭 성능을 두 배로 늘려야 하며, 이는 차례로 메모리 및 네트워크 대역폭의 두 배 증가로 지원되어야 합니다. 네트워크 대역폭은 이 차트의 오른쪽 상단에 있는 곡선에서 볼 수 있습니다."라고 그는 말했습니다.
"그 효과는 무엇입니까? 이는 GPU에 매우 가까이 가져와야 하는 고대역폭 메모리의 증가를 이끌어내며, 이는 차례로 더 높은 HBM 스택을 이끌어냅니다. 연결할 수 있는 더 많은 IO를 이끌어냅니다. 이는 실제로 더 큰 모듈 크기를 만들고 있습니다. 그리고 오른쪽 아래에서 볼 수 있듯이, 우리가 더 크고 더 큰 모듈 크기로 갈수록, 우리가 필요로 하는 것의 반대인 우리의 계산 요구를 지원하기 위해 훨씬 더 높은 전력을 이끌어내고 있습니다. 따라서 우리는 계산의 더 많은 지역성을 얻기 위해 노력해야 합니다."라고 Papermaster가 말했습니다.
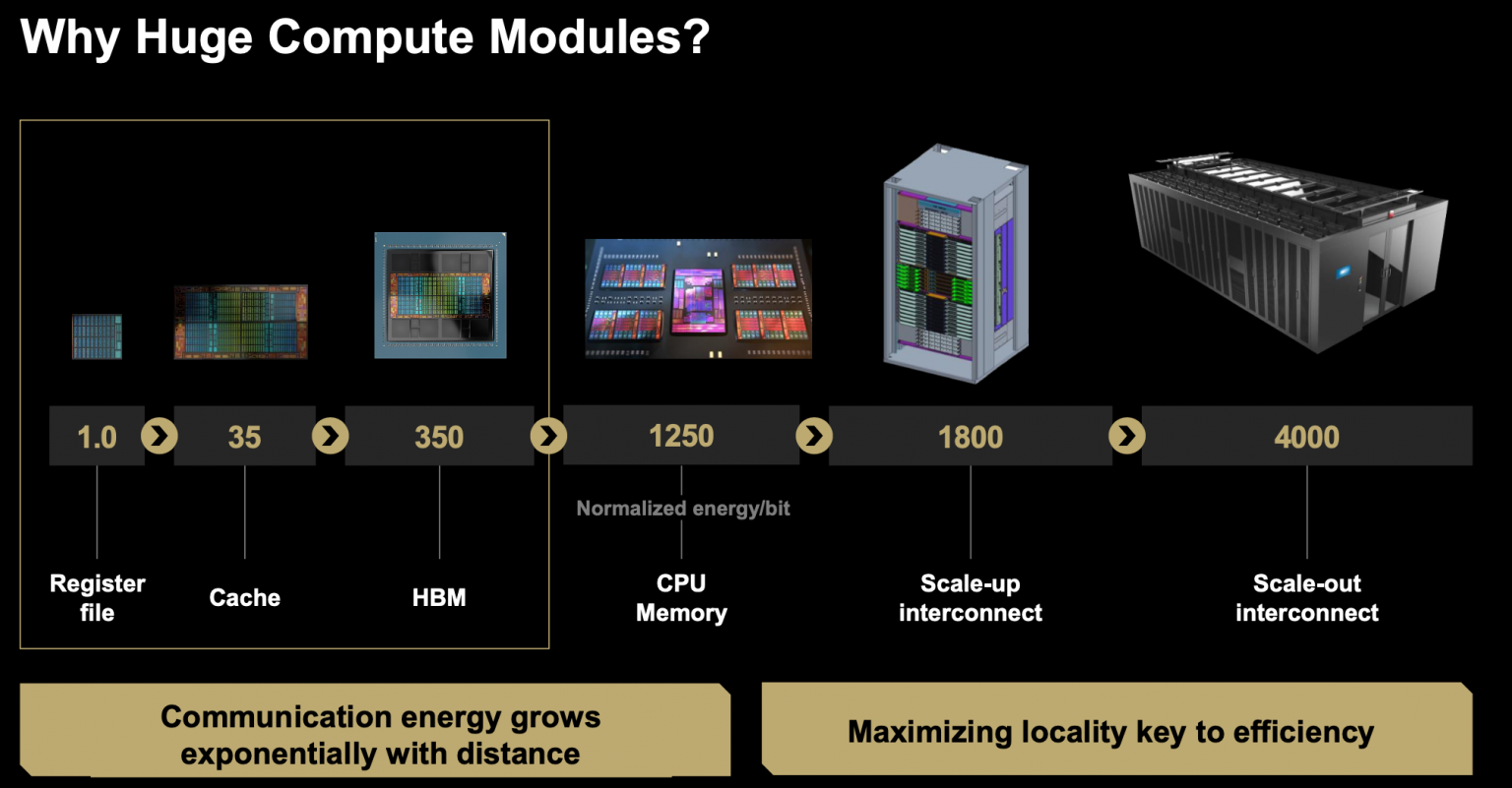

가장 낮은 수준의 통합에서 랙 규모까지 가면, 비트 전송에 소비되는 에너지, 주울 에너지의 엄청난 차이가 있습니다. "레지스터 파일에서 바로 옆에 있는 캐시로 비트가 전송되는 지역성이 있는 경우보다 랙 규모에 도달할 때까지 4000배 더 큽니다."라고 그는 말했습니다.
증가하는 에너지 소비를 제어하는 데 도움이 되는 효율성을 높여야 한다는 필요성은 Papermaster의 의견 전반에 걸쳐 강조되었습니다. 전체 비디오를 시청하는 것이 가치가 있습니다.
Atchley의 의견으로 넘어가서, 그는 리더십 시스템이 해결할 수 있는 어려운 문제의 증거로 Frontier에서 수행된 고급 HPC-AI를 보여주었습니다.
한 예는 프랑스의 Safran Aircraft Engines와 협력한 GE 항공우주의 파트너 프로젝트였습니다. 목표는 20% 더 연료 효율적인 엔진을 만드는 것입니다. 엔진이 더 효율적이 되는 방법은 더 넓어지는 것으로 밝혀졌습니다. 60년대 상업용 제트기의 사진을 보면, 엔진은 매우 좁고 매우 길었습니다. 하지만 여기(ISC2025)에 비행기로 왔다면 기내 엔진을 보면, 매우 넓지만 매우 짧다는 것을 알 수 있습니다. 엔진이 넓어질수록 더 효율적이 되지만, 어느 시점에서는 엔진을 넓게 만드는 것의 이점이 엔진 주변의 외부 껍질로 인한 추가 항력 때문에 손실됩니다.
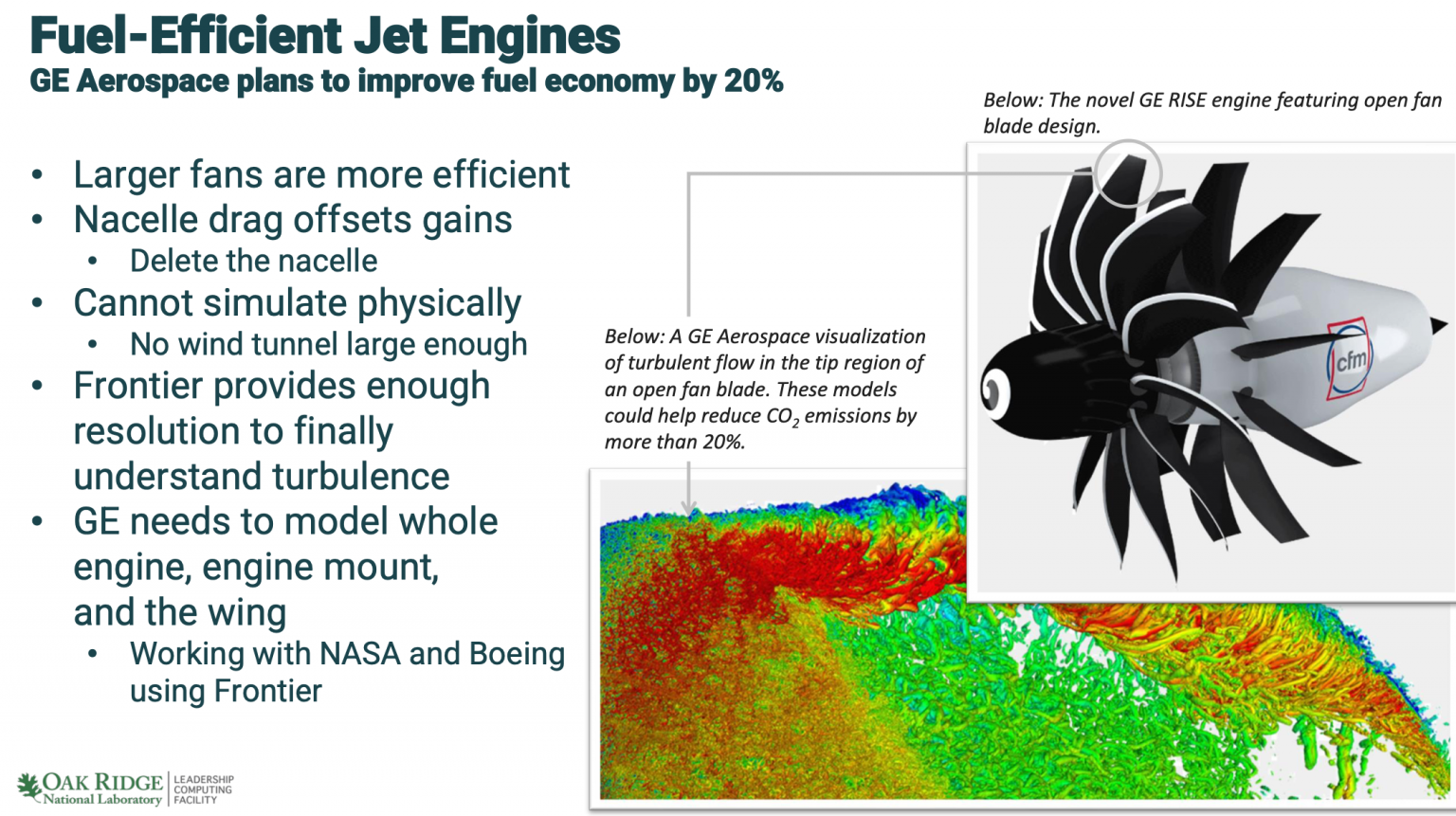
"그것을 해결하는 방법은 껍질을 제거하는 것입니다," Atchley가 언급했습니다. "이것은 새로운 아이디어가 아닙니다. 이 아이디어는 50년 동안 알려져 왔습니다. 문제는 소음입니다. 이러한 엔진이 있는 비행기를 타고 목적지에 도착하면 청각 장애가 생길 것입니다. 문제는 소음을 어떻게 제거하느냐는 것입니다. 소음은 난류이며, 난류는 모델링하기 매우 어렵습니다. 그들은 Titan 이후 이 작업을 해왔습니다. Mark가 언급한 Titan 시스템은 GPU가 있는 첫 번째 시스템으로, 규모면에서는 Kepler GPU가 있는 거의 19,000개의 노드였습니다. 그들은 이 작업을 했고, 그 다음 시스템인 Summit에서도 Volta가 있는 NVIDIA GPU로 진전을 이루었지만, 여전히 무슨 일이 일어나고 있는지 이해할 수 없었습니다."
"Frontier에서는 이제 이러한 와류에서 무슨 일이 일어나고 있는지 이해할 수 있는 충분한 메모리와 해상도, 충분한 성능이 있으며, 이제 그 소음을 줄이기 위한 설계 변경을 시작할 수 있습니다. GE는 Frontier에서의 이 작업이 그들의 일정을 수년 앞당겼다고 말했습니다. 그들은 이제 어떻게 전체 엔진을 모델링할 것인지에 대해 작업하고 있습니다. 이 엔진은 너무 커서 지구상의 어떤 풍동에도 맞지 않기 때문에, 이를 시뮬레이션할 수 있는 유일한 방법은 인실리코(컴퓨터 시뮬레이션)이며, 그들은 Frontier에서 그것을 하고 있습니다."
이 예는 고정밀 계산 집약적 워크로드를 강조했지만, Atchley는 OLCF와 DOE가 오랫동안 AI 기능을 구축해 왔다고 강조했습니다.

"우리는 과학을 위한 AI에 매우 관여하고 있습니다. 작년 슈퍼컴퓨팅[SC24]에서 Gordon Bell 결승진출자 중 세 명이 Frontier에서 낮은 정밀도를 사용했습니다. 그중 두 명은 AI를 사용했고, 한 명은 속도 향상을 위해 낮은 정밀도만 사용했으며, 첫 번째는 특별상 수상자였습니다. 이것을 언급하는 이유는 모델 시뮬레이션처럼 단지 플롭이 아니라, 단지 고정밀 플롭이 아니기 때문입니다. 메모리 용량이 필요합니다. 메모리 대역폭이 필요합니다. 스케일 업 대역폭과 스케일 업 대역폭이 필요합니다."라고 그는 말했습니다.
그렇다면 다음은 무엇일까요?
"Frontier 너머, 엑사스케일 너머에서 무엇을 기대하고 있을까요? 모델링과 시뮬레이션은 사라지지 않을 것입니다. 이 커뮤니티가 계속 성장할 것으로 예상할 수 있습니다. 그들에게는 대역폭이 필요합니다. 또한 FP64 지원이 필요합니다. 훈련할 데이터가 없다면, 그 데이터를 생성해야 하며, FP64를 사용하여 그것을 해야 합니다. 과학을 위한 AI는 현재 국립 연구소 커뮤니티 내에서 매우 중요합니다. 다시 말하지만, 프로세서에서 스케일 아웃 네트워크까지 모든 곳에서 대역폭이 필요합니다. 많은 저정밀 플롭이 필요합니다.
"또한 AI 워크로드에 맞춘 스토리지 시스템이 필요합니다. 모델 시뮬레이션에서 볼 수 있는 대규모 쓰기 액세스 또는 쓰기 패턴과 달리 더 많은 읽기 중심, 작은 랜덤 IO입니다. 우리는 시스템이 양자 컴퓨터에 연결할 수 있기를 원합니다. 그래서 하이브리드 클래식 양자 컴퓨팅을 할 수 있습니다."라고 Atchley가 언급했습니다.
두 발표 모두 내용이 풍부했으며, Q&A도 마찬가지였습니다.
상단 이미지: Papermaster가 보여준 AMD의 MI350 시리즈 GPU 사진