Gemini RAG 레시피와 쿼리 향상 기법

소개
생성형 AI는 이제 어디에나 존재하지만, LLM이 때때로 사용자 입력에 정확하게 응답하지 못하는 현상(환각 현상)이 자주 지적됩니다. 이때 검색 증강 생성(RAG)이 도움이 될 수 있습니다.
RAG는 LLM 모델 출력을 개선하기 위한 보편적인 기술이 되었습니다. 이 기술은 모델 학습 데이터에 없을 수 있는 외부 지식을 통합함으로써 출력을 향상시킵니다. RAG는 특정 도메인 지식과 데이터 프라이버시가 필요한 사용 사례에 특히 유용합니다.
RAG에 대해 더 알아보기 위해 로컬 컴퓨터에서 구현할 수 있는 RAG 레시피를 만들어 보겠습니다. 이 실습을 통해 RAG 시스템을 구현하는 방법을 배우고, 나중에 자신의 프로젝트나 실제 환경에서 활용할 수 있습니다.
RAG 레시피
RAG 시스템을 구현하는 방법은 다양합니다. 처음부터 구현하거나 프레임워크를 사용할 수 있고, 로컬 또는 호스팅된 LLM을 사용하거나, 호스팅된 벡터 데이터베이스 또는 로컬 구현을 선택할 수 있습니다. 어떤 RAG 접근 방식을 선택하든 결과가 안정적이고 충분히 정확하며 기술적 부채를 발생시키지 않는 것이 중요합니다.
우리의 구현에서는 쿼리 향상 기능이 포함된 표준 RAG 설정을 사용하여 결과를 개선하겠습니다. 로컬 벡터 데이터베이스와 호스팅된 언어 모델을 함께 사용할 것입니다. 아래 이미지에서 우리의 레시피를 확인할 수 있습니다.
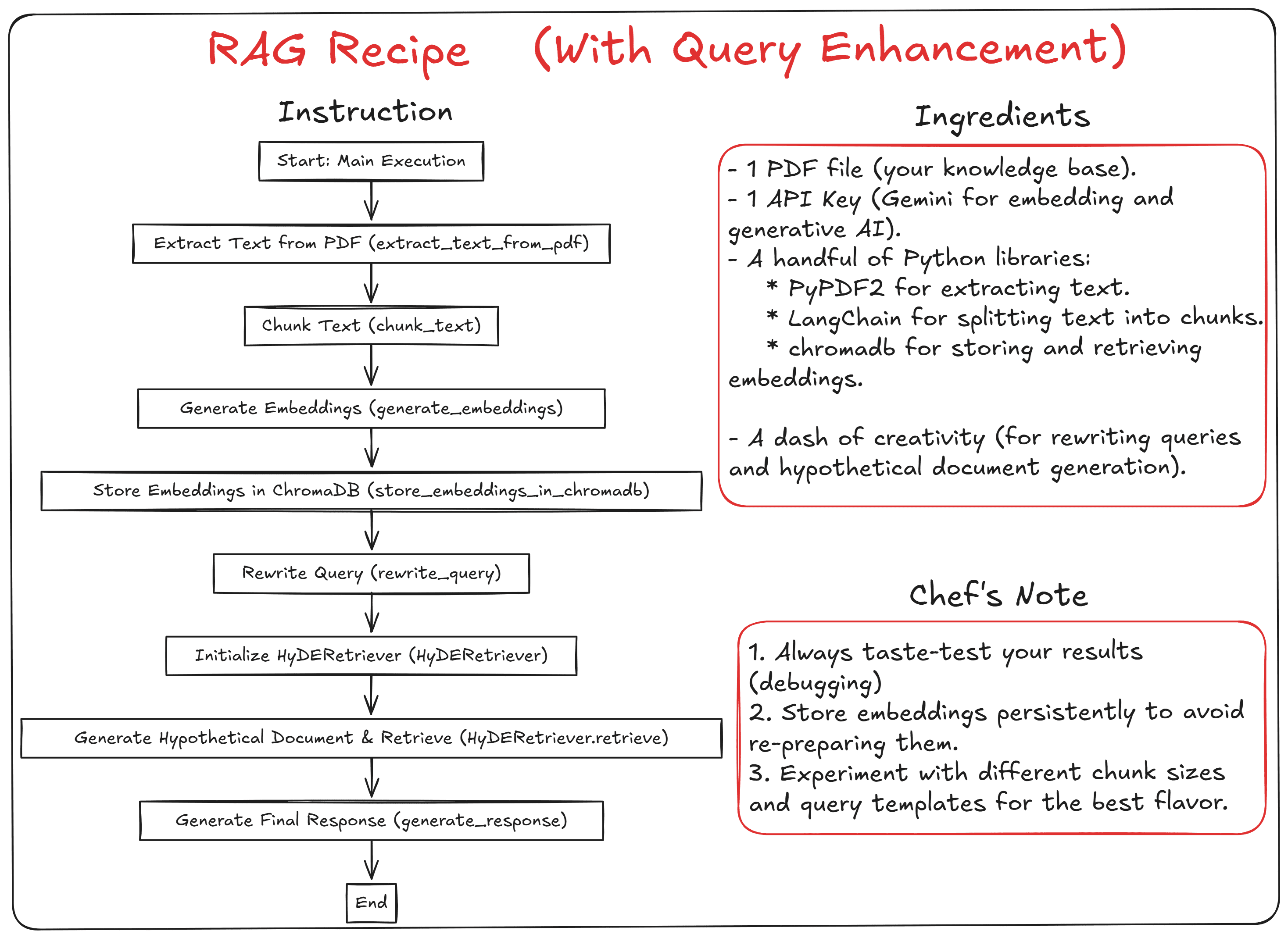
PDF 파일 내용을 지식 기반으로 사용하고, ChromaDB 벡터 데이터베이스에 저장할 것입니다. 임베딩과 생성형 AI에는 Gemini 제품군을 사용할 것입니다. 또한 쿼리 재작성과 가상 문서 임베딩 기법을 활용하여 생성된 결과를 개선할 것입니다.
쿼리 재작성은 검색에 사용되는 쿼리를 더 구체적이고 상세하게 만들어 개선하는 기법입니다. LLM을 사용하여 쿼리를 전달하고 더 나은 형태로 재구성합니다.
가상 문서 임베딩(HyDE)은 쿼리를 잠재적 답변을 포함한 가상 문서로 변환하여 개선하는 기법입니다. 이는 LLM을 사용하여 쿼리를 가상 문서로 확장함으로써 벡터 공간에서 쿼리와 문서 간의 의미적 격차를 좁히는 것을 목표로 합니다. 이렇게 생성된 가상 문서를 문서 검색에 활용합니다. 편의상 클래식 IDE 대신 Jupyter Notebook을 사용하겠지만, 원하는 방식으로 따라할 수 있습니다.
레시피 구현하기
먼저 가상 환경을 설정합니다:
```
python -m venv your-virtual-env-name
```
`.\Scripts\activate` 명령어로 가상 환경을 활성화한 후, 필요한 패키지를 설치합니다:
```
pip install PyPDF2 langchain google-generativeai chromadb
```
로컬 디렉토리에 `main.py` 파일을 생성하고 지식 데이터베이스로 사용할 PDF를 다운로드합니다. 여기서는 보험 핸드북을 사용하지만, 다른 PDF 파일을 사용해도 됩니다.
모든 준비가 완료되면, 쿼리 향상 기능이 있는 RAG 시스템을 위한 코드를 준비합니다. 먼저 필요한 패키지를 임포트하고 로거를 설정합니다:
```
import PyPDF2
from langchain.text_splitter import RecursiveCharacterTextSplitter
import google.generativeai as genai
import chromadb
import logging
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
logger = logging.getLogger(name)
```
그런 다음, RAG 시스템에 사용할 모든 함수를 준비합니다. 먼저 PDF 파일에서 텍스트를 추출하는 함수를 준비합니다:
```
def extracttextfrompdf(pdfpath):
logger.info(f"Extracting text from PDF: {pdf_path}")
with open(pdf_path, "rb") as file:
reader = PyPDF2.PdfReader(file)
text = ""
for page in reader.pages:
text += page.extract_text()
logger.info("Text extraction complete.")
return text
```
전체 PDF 텍스트를 생성형 AI에 그대로 전달하면 RAG의 가치가 감소합니다. 대신 LLM에 가장 관련성이 높은 결과를 전달하기 위해 원시 텍스트 데이터를 다음 함수를 사용하여 청크로 분할합니다:
```
def chunk_text(text):
logger.info("Splitting text into chunks...")
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50,
separators=["\n\n", "\n", " ", ""]
)
chunks = textsplitter.splittext(text)
logger.info(f"Text split into {len(chunks)} chunks.")
return chunks
```
문서당 500 토큰, 50 토큰 오버랩으로 설정했지만 실험을 통해 변경할 수 있습니다. 문서 분할에 정확한 매개변수는 없으므로 실험을 통해서만 최적의 매개변수를 찾을 수 있습니다.
문서가 준비되면 Gemini를 사용하여 임베딩으로 처리합니다:
```
genai.configure(api_key="YOUR-API-KEY")
def generate_embeddings(texts):
logger.info("Generating embeddings for text chunks...")
embeddings = []
for i, text in enumerate(texts):
logger.info(f"Generating embedding for chunk {i + 1}/{len(texts)}...")
result = genai.embed_content(
model="models/text-embedding-004",
content=text
)
embeddings.append(result['embedding'])
logger.info("Embeddings generated.")
return embeddings
```
모든 청크 임베딩은 어딘가에 저장되어야 합니다. 벡터 데이터베이스로 ChromaDB를 사용할 것입니다. ChromaDB를 사용하면 기본적으로 데이터가 로컬 디렉토리에 저장됩니다.
이를 설정하기 위해 청크 문서와 임베딩을 모두 저장하는 함수를 설정합니다:
```
def storeembeddingsinchromadb(chunks, chunkembeddings):
logger.info("Storing embeddings in ChromaDB...")
client = chromadb.Client()
# Change the collection name to your preferred name
collection = client.getorcreatecollection(name="insurancechunks")
ids = [f"chunk_{i}" for i in range(len(chunks))]
metadatas = [{"source": "pdf"}] * len(chunks) # Add metadata if needed
collection.add(
documents=chunks,
embeddings=chunk_embeddings,
metadatas=metadatas,
ids=ids #Unique ID for each documents
)
logger.info("Embeddings stored in ChromaDB.")
return collection
```
벡터 데이터베이스에 저장된 문서를 사용하여 RAG 시스템을 준비하겠습니다. 먼저 쿼리 재작성 함수부터 시작합니다:
```
def rewritequery(originalquery):
logger.info("Rewriting query...")
queryrewritetemplate = """You are an AI assistant tasked with reformulating user queries to improve retrieval in a RAG system.
Given the original query, rewrite it to be more specific, detailed, and likely to retrieve relevant information.
Original query: {original_query}
Rewritten query:"""
# Use Gemini to rewrite the query
model = genai.GenerativeModel("gemini-1.5-flash")
# Generate and return our response
response = model.generatecontent(queryrewritetemplate.format(originalquery=original_query))
logger.info("Query rewritten.")
return response.text
```
위 코드에서는 모델이 사용자 쿼리를 재구성하는 AI 어시스턴트 역할을 하는 프롬프트 템플릿을 준비했습니다.
다음으로, 가상 문서를 생성하고 벡터 데이터베이스에서 유사한 문서를 검색할 수 있는 HyDE 클래스를 준비합니다:
```
class HyDERetriever:
def init(self, collection, chunk_size=500):
self.collection = collection
self.chunksize = chunksize
def generatehypotheticaldocument(self, query):
logger.info("Generating hypothetical document...")
hyde_prompt = """Given the question '{query}', generate a hypothetical document that directly answers this question. The document should be detailed and in-depth.
The document size should be approximately {chunk_size} characters."""
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generatecontent(hydeprompt.format(query=query, chunksize=self.chunksize))
logger.info("Hypothetical document generated.")
return response.text
def retrieve(self, query, k=3):
logger.info("Retrieving relevant documents using HyDE...")
hypotheticaldoc = self.generatehypothetical_document(query)
hypotheticalembedding = generateembeddings([hypothetical_doc])[0]
results = self.collection.query(
queryembeddings=[hypotheticalembedding],
n_results=k
)
similar_docs = results["documents"][0]
logger.info(f"Retrieved {len(similar_docs)} relevant documents.")
return similardocs, hypotheticaldoc
```
쿼리 재작성과 HyDE를 모두 사용하면 RAG 결과를 개선할 수 있습니다. 설정은 쉽지만, 쿼리 결과가 여전히 원래 쿼리 의도를 따를 수 있도록 해야 합니다.
마지막으로, 쿼리에서 응답을 생성하는 함수를 설정합니다:
```
def generate_response(query, context):
logger.info("Generating response...")
prompt = f"Context: {context}\n\nQuestion: {query}\n\nAnswer:"
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content(prompt)
logger.info("Response generated.")
return response.text
```
실행하기
모든 준비가 완료되면, 다음 코드로 RAG 시스템을 설정하고 실행합니다:
```
if name == "main":
try:
# Step 1: Extract and chunk text
pdfpath = "InsuranceHandbook_20103.pdf"
logger.info(f"Starting process for PDF: {pdf_path}")
text = extracttextfrompdf(pdfpath)
chunks = chunk_text(text)
# Step 2: Generate embeddings
chunkembeddings = generateembeddings(chunks)
# Step 3: Store embeddings in ChromaDB
collection = storeembeddingsinchromadb(chunks, chunkembeddings)
# Step 4: Rewrite the query
original_query = "What is residual markets in insurance?"
rewrittenquery = rewritequery(original_query)
logger.info(f"Rewritten Query: {rewritten_query}")
# Step 5: Retrieve relevant documents using HyDE
hyde_retriever = HyDERetriever(collection)
similardocs, hypotheticaldoc = hyderetriever.retrieve(rewrittenquery)
logger.info(f"Hypothetical Document: {hypothetical_doc}")
logger.info(f"Similar Documents: {similar_docs}")
# Step 6: Generate a response
context = " ".join(similar_docs)
response = generateresponse(originalquery, context)
logger.info(f"Generated Response: {response}")
except Exception as e:
logger.error(f"An error occurred: {e}", exc_info=True)
```
PDF 경로와 원래 쿼리를 사용하려는 것으로 바꿉니다. 다음 명령어로 실행합니다:
```
python main.py
```
로깅 프로세스를 통해 RAG 시스템의 모든 과정을 확인할 수 있습니다. 예를 들어, "What is residual markets in insurance?"라는 간단한 쿼리에서 재작성된 쿼리 결과는 다음과 같습니다:
```
Rewritten Query: Explain the concept of residual markets in the insurance
industry, including the types of risks typically covered, how they operate,
and the regulatory frameworks governing their function in the United States
and/or [Specify a relevant country/region, if known]. Provide examples of
specific residual market mechanisms, such as state-sponsored insurance pools
or assigned risk plans.
```
재작성된 쿼리를 바탕으로 다음과 같은 가상 문서가 생성됩니다:
```
Hypothetical Document: Residual markets in insurance address risks deemed
too hazardous or unprofitable for the private sector. These markets, often
government-backed or mandated, provide coverage of last resort. In the US,
they include state-sponsored pools (e.g., for high-risk auto insurance) and
assigned risk plans, where insurers share responsibility for covering
high-risk individuals. Coverage typically encompasses auto insurance,
workers' compensation, and occasionally property insurance in high-risk
areas. Operation involves assessing risk, setting premiums (often higher
than private market rates), and distributing costs among participating
insurers. State regulations govern participation, rate setting, and solvency.
Strict oversight aims to prevent market distortions while ensuring access to
essential insurance. The system balances the need for widespread coverage
with the avoidance of excessive burdens on insurers and taxpayers
```
위의 가상 문서를 사용하여 시스템은 벡터 데이터베이스에서 가장 관련성 높은 문서를 찾아 LLM에 전달합니다. 질문에 대한 답변으로 생성된 결과는 다음과 같습니다:
```
Generated Response: In insurance, residual markets refer to the business that
insurers do not voluntarily assume. This is because the risks involved are
considered high, and insurers would typically avoid them in a competitive market.
These markets are also sometimes called "shared" markets because profits and
losses are shared among all insurers in a state offering that type of insurance,
or "involuntary" markets because participation isn't a choice for insurers.
Residual market programs often require some form of government intervention
or support because they are rarely self-sufficient.
```
이것으로 Gemini RAG 레시피가 완성되었습니다. 이를 쉽게 응용하여 쿼리 향상 기능을 추가하고 결과를 개선하는 자신만의 시스템을 개발할 수 있습니다.
마무리
RAG는 LLM 모델의 기존 지식에 외부 지식을 통합하여 생성된 출력을 개선하는 기술입니다. RAG는 특정 도메인 지식과 데이터 프라이버시가 필요한 사용 사례에 유용합니다.
이 글에서는 Gemini 언어 모델, ChromaDB 벡터 데이터베이스, 쿼리 향상 기법을 사용하여 RAG 구현 레시피를 만드는 방법을 배웠습니다.