10가지 판다스 한 줄 코드로 하는 탐색적 데이터 분석

새로운 데이터셋을 분석할 때 빠르게 이해할 수 있는 방법이 있으면 좋겠다고 생각해 본 적이 있나요? 데이터 전문가라면 누구나 데이터셋을 보며 그 안에서 유용한 정보를 찾으려 고민해본 경험이 있을 것입니다. 이럴 때 판다스 한 줄 코드가 큰 도움이 됩니다.
이 글에서는 탐색적 데이터 분석(EDA)에 유용한 판다스 한 줄 코드 10가지를 소개합니다. Seaborn flights 데이터셋을 예시로 사용하겠습니다.
1. 데이터셋 빠르게 살펴보기
이 간단한 명령어로 데이터셋의 행과 열 수, 열 이름, 데이터 타입, 널이 아닌 값의 개수 등 전반적인 정보를 얻을 수 있습니다. 이를 통해 누락된 값과 데이터 구조를 즉시 파악할 수 있습니다.
```
flights.info()
```
출력:
```
RangeIndex: 144 entries, 0 to 143
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 144 non-null int64
1 month 144 non-null category
2 passengers 144 non-null int64
dtypes: category(1), int64(2)
memory usage: 2.9 KB
```
2. 누락된 값 확인하기
누락된 데이터는 분석에 큰 영향을 미칠 수 있습니다. 이 한 줄 코드는 열별로 누락된 값의 개수를 보여주어 이를 처리하는 방법을 결정하는 데 도움이 됩니다.
```
flights.isna().sum()
```
출력:
```
0
year 0
month 0
passengers 0
dtype: int64
```
좋습니다! 이 데이터셋에는 누락된 값이 없습니다.
3. 통계 요약 생성하기
이 명령어는 모든 열에 대한 포괄적인 통계 요약을 제공합니다. 숫자 데이터의 개수, 평균, 표준편차, 최소값, 최대값, 사분위수와 범주형 열에 대한 유용한 정보를 보여줍니다.
```
flights.describe()
```
출력:
```
year passengers
count 144.000000 144.000000
mean 1954.500000 280.298611
std 3.464102 119.966317
min 1949.000000 104.000000
25% 1951.750000 180.000000
50% 1954.500000 265.500000
75% 1957.250000 360.500000
max 1960.000000 622.000000
```
4. 범주형 열의 고유 값 식별하기
범주형 변수의 고유성을 이해하는 것은 필수적입니다. 이 한 줄 코드는
각 범주형 열의 고유 값 개수를 딕셔너리 형태로 반환합니다.
```
{col: flights[col].nunique() for col in flights.select_dtypes(include=['category', 'object']).columns}
```
출력:
```
{'month': 12}
```
예상대로 12개의 고유한 월이 있습니다.
5. 변수 간 상관관계 찾기
이 코드는 모든 수치형 변수의 상관관계 행렬을 계산하여 변수 간 관계를 파악하는 데 도움이 됩니다.
```
flights.corr()
```
6. 그룹별 집계 계산하기
이 한 줄 코드는 범주형 변수로 데이터를 그룹화하고 한 번에 여러 통계를 계산합니다.
```
flights.groupby('month')['passengers'].agg(['mean', 'min', 'max', 'std'])
```
출력:
```
mean min max std
month
Jan 241.750000 112 417 101.032960
Feb 235.000000 118 391 89.619397
Mar 270.166667 132 419 100.559194
Apr 267.083333 129 461 107.374839
May 271.833333 121 472 114.739890
Jun 311.666667 135 535 134.219856
Jul 351.333333 148 622 156.827255
Aug 351.083333 148 606 155.783333
Sep 302.416667 136 508 123.954140
Oct 266.583333 119 461 110.744964
Nov 232.833333 104 390 95.185783
Dec 261.833333 118 432 103.093808
```
이를 통해 월별 승객 수의 계절적 패턴과 평균값을 확인할 수 있습니다.
7. IQR 방법으로 이상치 식별하기
이 한 줄 코드는 사분위범위(IQR) 방법을 사용하여 이상치를 식별합니다. Q1 - 1.5IQR 미만이거나 Q3 + 1.5IQR 초과인 값은 이상치로 간주됩니다.
```
Q1, Q3 = flights['passengers'].quantile(0.25), flights['passengers'].quantile(0.75); flights[(flights['passengers'] < Q1 - 1.5 (Q3 - Q1)) | (flights['passengers'] > Q3 + 1.5 (Q3 - Q1))]
```
이 데이터셋에는 이상치가 없습니다.
8. 시계열 추세 플롯 생성하기
시간에 따른 추세를 시각화하는 것은 시계열 데이터에서 중요합니다. 이 한 줄 코드는 연도별 승객 수 변화를 보여주는 플롯을 생성합니다.
```
flights.plot(x='year', y='passengers', figsize=(12, 6), title='Passenger Trend Over Time')
```
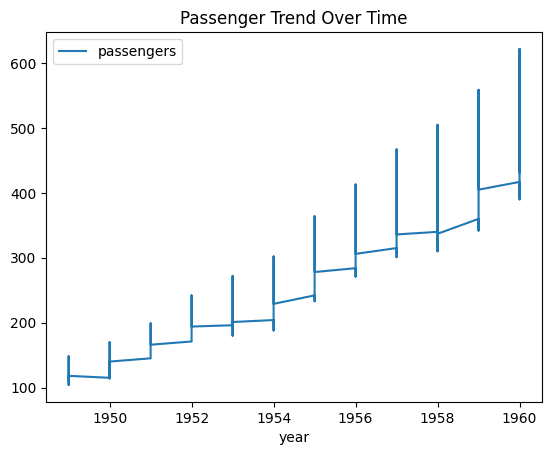
9. 기간별 변화 계산하기
이 한 줄 코드는 이전 기간 대비 백분율 변화를 계산하여 성장률을 이해하는 데 도움이 됩니다.
```
flights.assign(pctchange=flights['passengers'].pctchange() * 100)
```
출력:
```
year month passengers pct_change
0 1949 Jan 112 NaN
1 1949 Feb 118 5.357143
2 1949 Mar 132 11.864407
3 1949 Apr 129 -2.272727
4 1949 May 121 -6.201550
... ... ... ... ...
139 1960 Aug 606 -2.572347
140 1960 Sep 508 -16.171617
141 1960 Oct 461 -9.251969
142 1960 Nov 390 -15.401302
143 1960 Dec 432 10.769231
144 rows × 4 columns
```
이는 승객 수의 월별 백분율 변화를 보여줍니다.
10. 계절적 패턴 분해하기
이 한 줄 코드는 데이터를 행은 연도, 열은 월로 하는 행렬 형식으로 변환한 다음, 연도별 계절적 패턴을 보여주는 시각화를 생성합니다.
```
flights.pivot(index='year', columns='month', values='passengers').plot(figsize=(14, 8), title='Monthly Passenger Counts by Year')
```
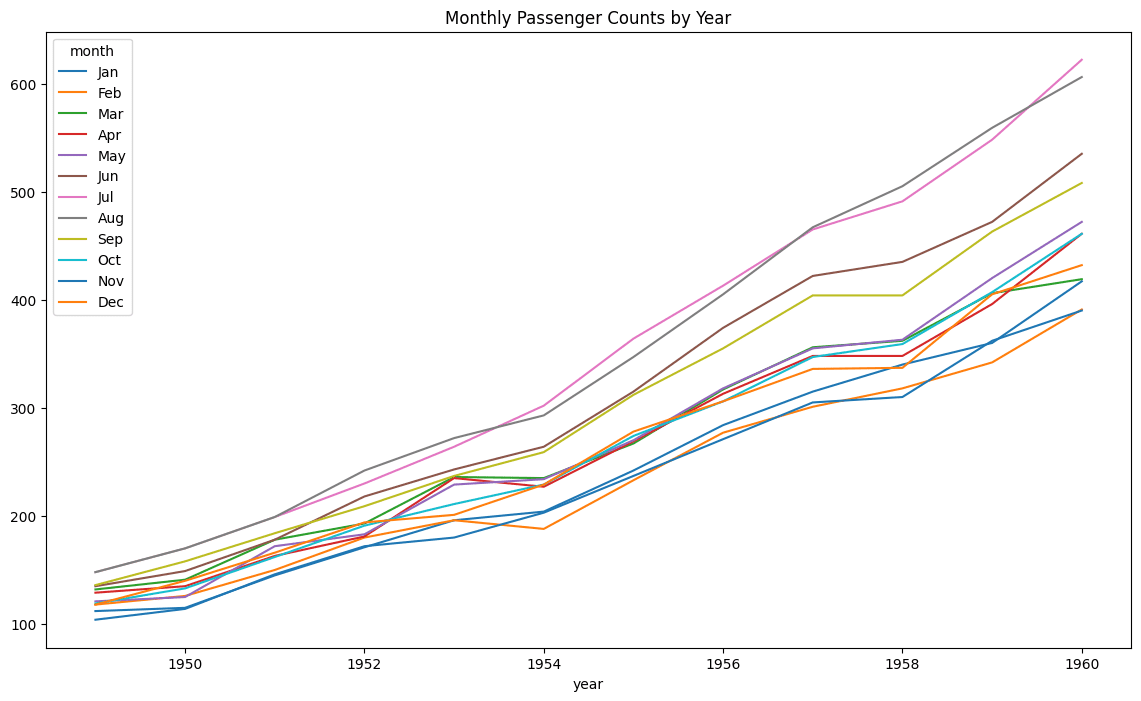
이는 각 연도별 월별 승객 수를 보여주는 라인 플롯으로, 계절적 패턴을 확인할 수 있습니다.
마무리
이 10가지 판다스 한 줄 코드를 통해 탐색적 데이터 분석을 수행하는 방법을 살펴보았습니다. 이러한 기법들을 조합하면 어떤 데이터셋의 구조, 내용, 패턴도 빠르게 파악할 수 있습니다.
행복한 데이터 분석 되세요!